
Entrenar Stable Diffusion con Dreambooth fácil y gratis
El otro día veíamos cómo generar imágenes de nosotros mismos entrenando y utilizando Stable Diffusion con Dreambooth, por aquellas fechas el método aun no había sido perfeccionado y requería de instancias virtuales de pago, además de ser un proceso largo y tedioso para alguien sin experiencia. En la actualidad ya se puede hacer de forma faćil y gratuita siguiendo unos pequeños pasos.
Lo primero es acceder a la página de Google Colab dónde ejecutaremos un script paso a paso, consta de siete, el último de todos es para generar las imágenes con nuestro modelo ya entrenado haciendo uso de la herramienta creada por AUTOMATIC1111.
La herramienta para el entrenamiento ha sido creada por DotCSV, mientras que el de generación por TheLastBen.
Antes de empezar con el entrenamiento, arriba en el menú de opciones tenemos que cambiar el entorno de ejecución a GPU dónde dice Entorno de ejecución -> Cambiar tipo de entorno de ejecución.
Entrenamiento del modelo
El entrenamiento se realiza una única vez, al terminar se nos generará un fichero ckpt con nuestro concepto ya integrado en Stable Diffusion, ese fichero lo tendremos que utilizar cuando vayamos a generar las imágenes incluyendo nuestro concepto.
Este modelo entrenado es tuyo y privado, si lo compartes con alguien podrán generar imágenes en las que aparezca el concepto integrado por lo que actúa con responsabilidad y piénsate dos veces lo de compartirlo, no sabes para qué puede ser utilizado.
Para entrenar Stable Diffusion con el concepto que queramos crear ya sea nosotros mismos, un amigo y/o familiar siempre y cuándo tengamos su permiso tenemos que ir ejecutando los dos primeros pasos pulsando en el símbolo Play ubicado en la izquierda del paso a ejecutar al posicionar el cursor sobre el mismo.
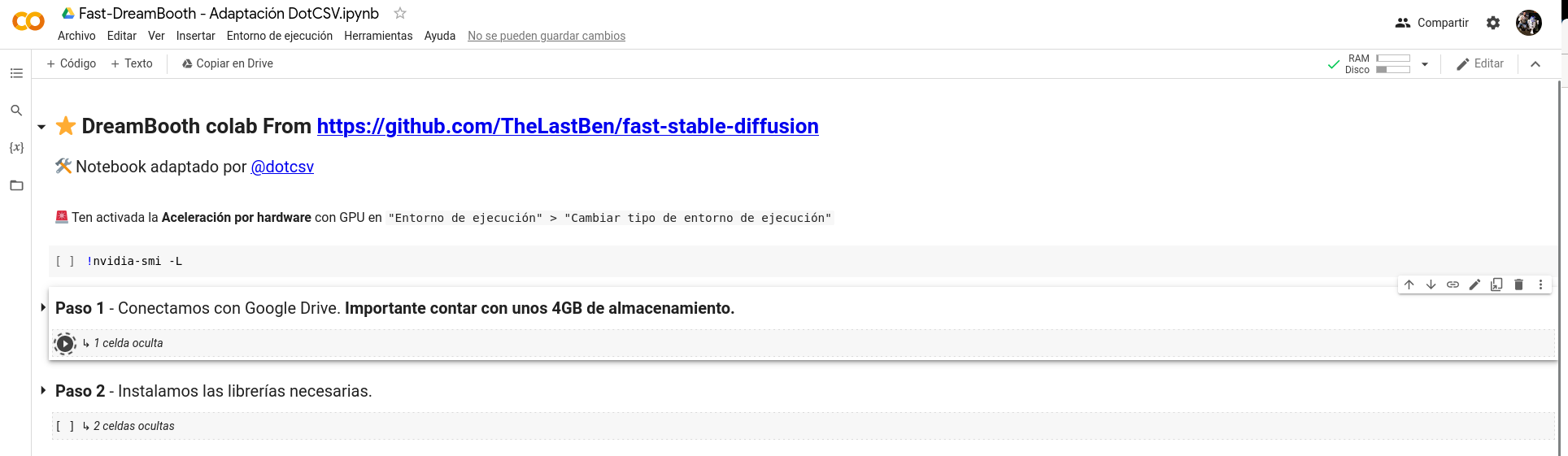
Al ejecutar el primer paso nos solicitará permisos para conectar con nuestra cuenta de Google Drive, en ella se almacenarán los ficheros necesarios para el proceso. Una vez aceptados los permisos un icono de carga aparecerá en el de play y se pondrá a girar hasta que el paso termine, una vez hecho podemos proceder con el siguiente que no requiere configuración ninguna.
El tercer paso nos pide conectar nuestra cuenta a HuggingFace a través de su API, es necesario para descargar el modelo original previamente entrenado para poder trabajar sobre él. Es necesario también solicitar acceso al mismo para que este paso se complete satisfactoriamente. Sólo tenemos que acceder a nuestro perfil en la página y copiar el código que ahí se nos muestra en la caja de texto que dice HuggingFace_Token.

En caso de tener el modelo ya previamente entrenado aquí podemos indicarle la ruta de nuestro Google Drive para cargarlo si sólo vamos a generar imágenes y no entrenarlo.
Podemos extender el paso actual para ver si ha terminado o no, de ser así aparecerá una marca de verificación de color verde en la parte izquierda.
Una vez terminado de descargar el modelo original de Stable Diffusion vamos a configurar las condiciones del entrenamiento en el paso 4. Crearemos una carpeta en nuestro Google Drive llamada miconcepto dónde almacenaremos nuestras fotos, dentro de lo posible es recomendable redimensionarlas a 512×512 todas ya que si no puede pasar que las proporciones del concepto integrado en las imágenes generadas no sean correctas.
Con ellas en Google Drive configuramos los parámetros necesarios:
Training_Subject:El tipo de concepto a integrarWith_Prior_Preservation:Indica que el concepto se ha de integrar sobre el modelo original de Stable Diffusion y no será lo único que aparezca en las imágenes a generar.SUBJECT_TYPE: El tipo de sujeto a integrar, un perro, una persona, etc.INSTANCE_NAME: El texto con el que Stable Diffusion conocerá al concepto integrado, si es nuestra persona podemos poner nuestro nombre y apellidos todos juntos en minúsculas, teniendo en cuenta que si coincide con el de una persona famosa o algo parecido probablemente los confunda después, tiene que ser algo que nos identifique y «único», si es corto mejor ya que vamos a tener que escribirlo muchas veces.INSTANCE_DIR_OPTIONAL: La ruta a nuestras imágenes en Google Drive, la obtenemos desde el menú contextual del panel izquierdo sobre la carpeta que las contiene.Number_of_subject_images: La cantidad de fotos de la carpeta a ser utilizadas para el entrenamiento, con unas 15 se pueden obtener unos resultados muy buenos pero cuantas más mejor.

El paso 5 nos permite descargar imágenes de ejemplo para ayudar a la Inteligencia Artificial a comprender mejor el concepto que se pretende añadir, por ejemplo para una persona (person_ddim), descargará imágenes de ejemplo con las que acompañar al concepto, básicamente fotos de otras personas en diferentes ambientes, posturas, estilos, etc.
Llegados al paso del entrenamiento, número 6 podemos ejecutarlo sin más y dejarlo el tiempo requerido, puede tardar bastante dependiendo de la capacidad de procesamiento que se te haya asignado. Al terminar nos guardará en la carpeta el fichero miconcepto.ckpt que utilizaremos después para generar las imágenes.
Podemos probar el resultado final ejecutando el paso 7, nos dará un enlace al que acceder con una página web en la que introducir los textos y los diferentes parámetros.
El entrenamiento del modelo como decíamos al principio sólo se realiza una única vez, podríamos querer actualizarlo en caso de que mejorasen el modelo original de Stable Diffusion y queremos utilizar las nuevas funcionalidades, mientras tanto, con el fichero final ya podemos generar nuestras creaciones.
Generación de imágenes
Con nuestro fichero ya entrenado estamos preparados para utilizar la herramienta de AUTOMATIC1111. Una vez allí (tras modificar el entorno de ejecución por GPU) podemos ejecutar el primer paso para conectar a Google Drive y el segundo para instalar la herramienta.
Podemos obtener la ruta mediante el menú contextual del panel izquierdo sobre el nombre de nuestro fichero entrenado ckpt que tendremos que pegar en el parámetro Path_to_trained_model

Empezamos el proceso de descarga para luego instalar los requisitos necesarios y arrancar Stable Diffusion, nos proporcionará un enlace al que acceder con la herramienta lista para empezar a crear.
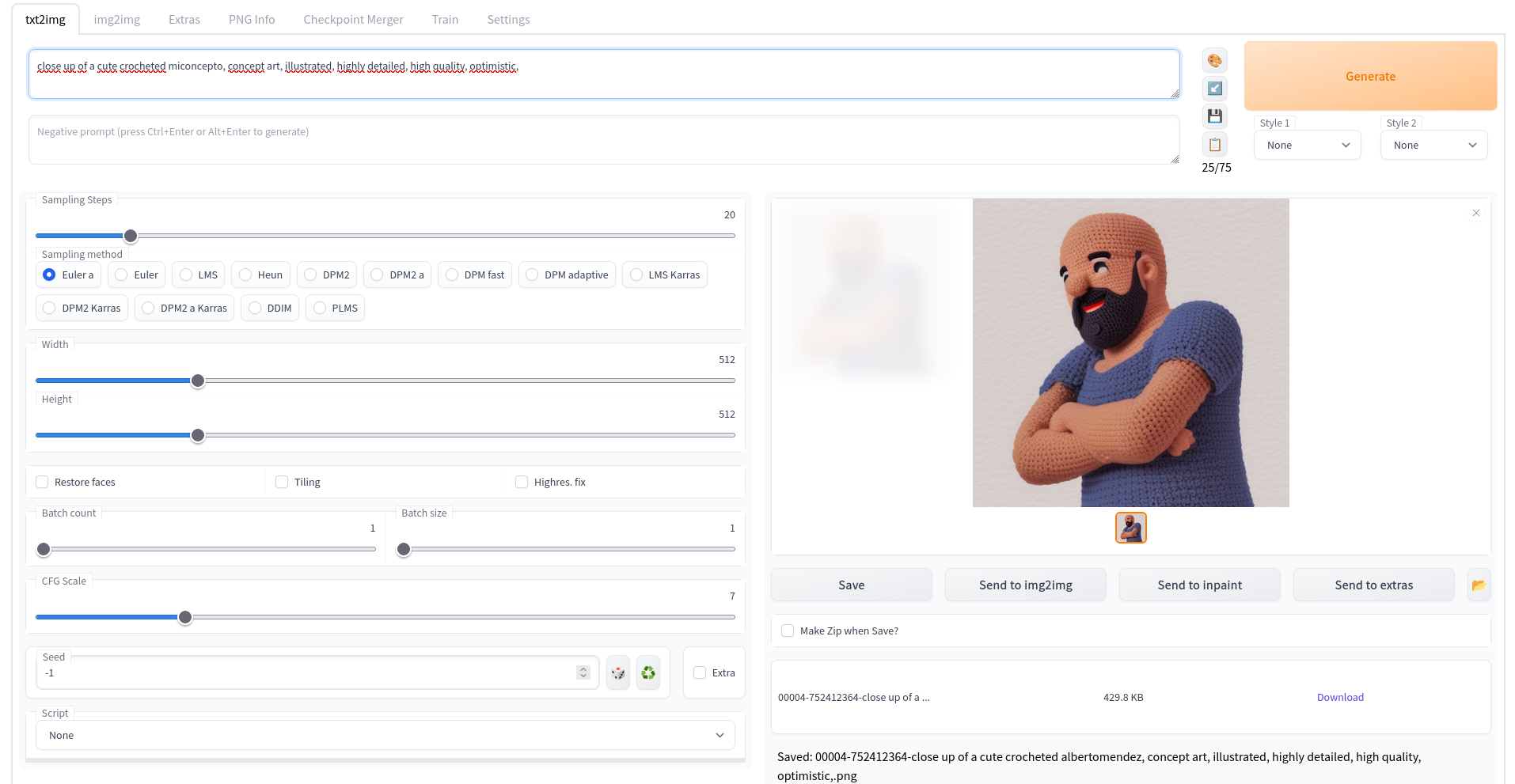
Al acceder a la herramienta nos encontramos con varias opciones importantes:
- La primera caja para introducir el texto de entrada (
prompt). Para resultados óptimos se recomienda que sean en Inglés. Tiene que incluir la palabramiconceptosi queremos que éste aparezca en la misma Sampling steps: Número de pasos que debe realizar el algoritmo para generar la imagen, afectará a la calidad finalBatch Size: Número de imágenes a generarSeed: La semilla para generar la imagen, con una similar podremos crear variaciones sobre la misma imagenCFG Scale: Cuánto más alto más se aproximará al texto de entrada
Ya conocemos las posibilidades de la generación de imágenes por Inteligencia Artificial y ahora también sabemos cómo utilizarlas para nuestros propósitos, ahora sólo falta dejar fluir la imaginación.









Un buen catálogo de creaciones con Stable Diffusion y sus textos de entrada puede encontrarse en Lexica Art para ayudar a inspirarte. Asegúrate de copiar también el seed y el CFG para un resultado satisfactorio.
Te puedo asegurar que los resultados en mi caso son más que óptimos, la proporción de resultados buenos ha aumentado con respecto al entrenamiento del artículo original, anímate, atrévete a crear el tuyo o de tu mascota y comparte los resultados si quieres, cualquier duda o comentario déjalo abajo.
Relacionado
- Script de entrenamiento: Google Colab
- Script de generación de imágenes: Google Colab
- Stable Diffusion: Stability.ai
- Dreambooth: Github
Desarrollador de software, informático, emprendedor y entusiasta por la tecnología desde tiempos inmemoriales. Inquieto por defecto, curioso por naturaleza, trato de entender el mundo y mejorarlo utilizando la tecnología como herramienta.
¿Se puede entrenar la ia con un mismo archivo ckpt para dos cosas distintas?
Ejemplo: Crear un avatar con mi cara y a su vez crear un brazalete, o un estilo de armadura con mi diseño unico que quiero que mi personaje use.
Hola Jose, pues la verdad no se decirte al 100%, he visto que hay algunos tutoriales para entrenarla con varias personas, pero no lo he visto con diferentes conceptos (persona y objeto en este caso). Todo sería probar a seguir los pasos del proceso múltiple cambiando los conceptos pero no sé con certeza si se puede. Saludos
Hola buenas, muy buen artículo,
Tenía una pregunta a relación con el primer comentario, si yo entreno un modelo con un concepto de cara y ya lo tengo entrenado, y luego quiero volver a entrenarlo con una persona completa, en que paso indicó que sea mi modelo preentrenado el que use para reentrenarlo??
Hola Unai, para entrenar un modelo con un concepto ya integrado tendrías que subirlo (supongo que te permitirá añadir tu fichero «.ckpt» si no con los ficheros generados del modelo) a Hugging Face aunque sea en privado y cargarlo en el punto del tutorial en el que se obtiene la versión original de Stable Diffusion. De todas formas, si vas a entrenarlo con el «cuerpo» de la misma persona y también contiene la cara te recomiendo hacerlo desde cero, puedes añadir todas las fotos (cara sólo y cuerpo con cara) al nuevo entrenamiento, depende los resultados que quieras obtener.
Graias por el post, tengo una pregunta, si tengo un set de 100 imagenes para entrenar el modelo de una persona, cuantos Training_Steps deberia usar? habia leido de una regla de que deben ser 100 pasos por cada imagen, eso es correcto? en ese caso debo usar 10.000 pasos para ese set de 100 imagenes?
Hola Cesar, por lo que tengo entendido no existe una fórmula óptima para calcular el número de pasos para entrenar el modelo mediante Dreambooth, no sólo depende del número de imágenes sino también de su contenido. Según una publicación en Hugging Face: «Para obtener imágenes de buena calidad, debemos encontrar un ‘punto óptimo’ entre el número de pasos de entrenamiento y la tasa de aprendizaje. Recomendamos utilizar una tasa de aprendizaje baja e ir aumentando progresivamente el número de pasos hasta que los resultados sean satisfactorios». También nos dice que el número de pasos para entrenarlo suele ser más alto si se trata sólo de caras o que si las imágenes salen con mucho ruido se puede aumentar el número en un valor de 100 aproximadamente, así que lo mejor es ir probando.