
Entrenar a la Inteligencia Artificial para generar imágenes de nosotros mismos
Está en boca de todos, empezamos a ver los primeros casos útiles de los algoritmos de Inteligencia Artificial y ya hay conflicto, lo que falta por venir… Lo que está claro es que como herramienta son muy útiles por lo que vamos a hacer un pequeño experimento con alguno de ellos, entrenaremos a Stable Diffusion con Dreambooth para generar imágenes de nosotros mismos en cualquier situación que se nos ocurra.
ACTUALIZACIÓN: Este proceso ha sido mejorado y puede realizarse de forma gratuita siguiendo los pasos aquí indicados.
¿No es impresionante? Y más fácil de lo que crees.
Este proceso consume una alta cantidad de recursos y requiere de tarjetas gráficas especiales de miles de euros para poder realizarlo uno en casa pero haciendo uso de los servicios disponibles en la nube podremos entrenar nuestro modelo por menos de 30€ (yo pagué 32€ por unas horas de investigación), una vez creado nuestro Stable Diffusion personalizado ya podremos generar imágenes gastando una ínfima parte de lo que supone la creación del mismo.
Los requisitos son:
- Conocimientos básicos de informática
- Cuenta en Google Cloud Platform: En ella crearemos una máquina virtual con una tarjeta gráfica especializada para algoritmos de Inteligencia Artificial, lo contrataremos por el tiempo en que la máquina esté activa (IMPORTANTE: Eliminarla al terminar para no seguir generando costes). El coste de la instancia es de alrededor de 3€ la hora, cuenta por el tiempo en que la máquina esté activa, aun estando detenida.
- Cuenta en Hugging Face: De sus repositorios obtendremos la versión original de Stable Diffusion, es open source y gratuita.
Instancia Virtual en Google Cloud Platform
Empezaremos creando la instancia en la nube de Google, para ello desde la consola de la plataforma le damos a Crear una VM y en el formulario de configuración cambiamos lo siguiente:
Nombre: Simplemente para tenerla identificada, podemos poner lo que queramos.- Para
regiónyzonahay que seleccionar una disponible ya que no todas permiten el uso de estas tarjetas gráficas, además depende de dónde nos encontramos, cuánto más cerca esté de nuestra ubicación más rápida la comunicación de datos y diferentes opciones disponibles, el propio formulario nos indicará si la zona permite el uso del hardware seleccionado o no. - En
Familia de máquinasdentro deConfiguración de la máquinaseleccionamos la opciónGPUy abajo la tarjeta gráficaNvidia A100 40GBsi está disponible, lo demás por defecto. - Disco de arranque: Al final de esta sección hay un botón que dice
Cambiar, lo presionamos para seleccionar la versión de Debian optimizada para IA (Debian 10 based Deep Learning VM with M97) y abajo ponemos 100 en el campo de texto para introducir la cantidad de GB de almacenamiento en disco. - En
Cuentas de serviciodentro deIdentidad y acceso a la APIseleccionar la de Compute Engine por defecto. - Para terminar permitimos
HTTPyHTTPS.
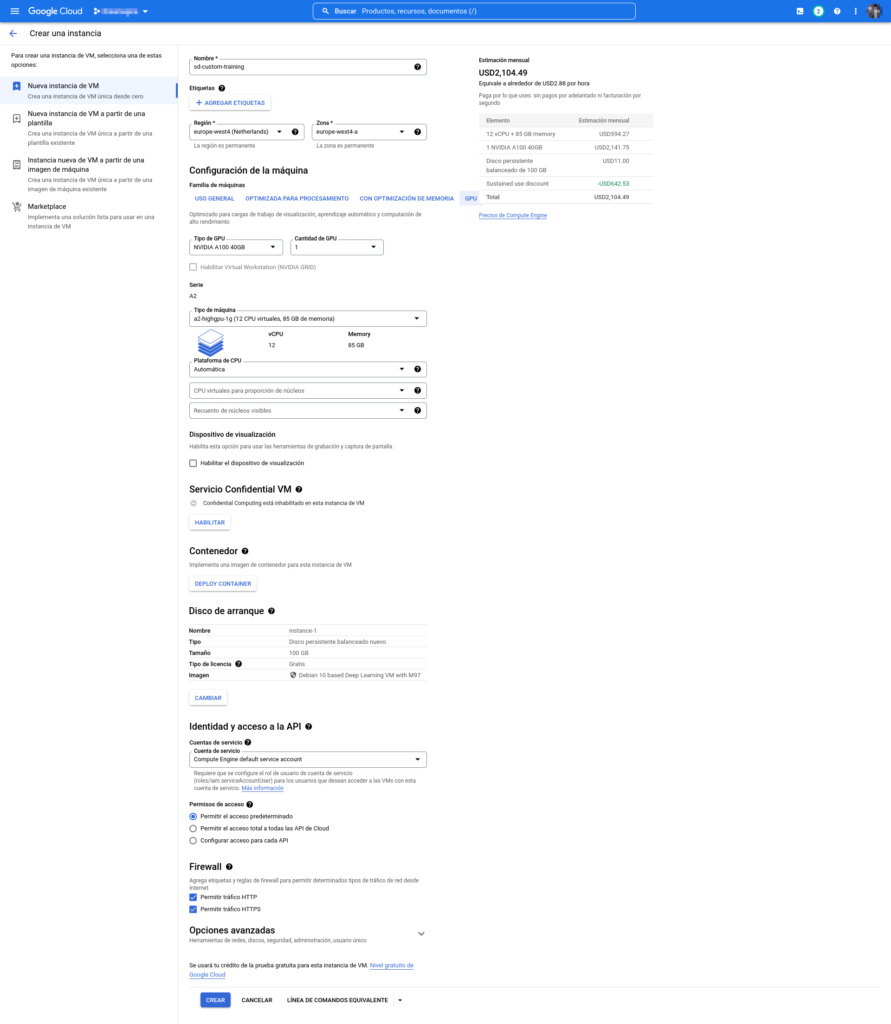
En cuanto le demos a crear puede pasar que nos la denieguen ya que el uso de estas tarjetas graficas está muy controlado por Google ya que como decía antes consumen una gran cantidad de recursos, su disponibilidad es limitada y su coste muy alto. De ser así nos ofrecerán un formulario preguntando cuántas tarjetas gráficas necesitaríamos y porqué, bastaría con escribirles que vamos a entrenar un nuevo modelo de Stable Diffusion para que nos concedan la cuota necesaria para utilizarla. Si no hay problemas la instancia se iniciará nada más termine de crearse.
Hay que crear la instancia de nuevo una vez nos concedan la cuota de uso de la tarjeta gráfica en caso de habérnosla denegado en un primer momento.
Configuración del entorno
Conectaremos a ella por SSH utilizando el cliente de Google Cloud Platform que podemos instalar desde aquí, el enlace de conexión lo vemos en la consola de GCP en la flecha al lado del botón SSH seleccionando la opción de conexión por gcloud.
Le decimos que sí a la pregunta de si queremos instalar los drivers de Nvidia, cuando termine descargaremos la versión de Stable Diffusion con Dreambooth de su Github y configuraremos el entorno:
git clone https://github.com/XavierXiao/Dreambooth-Stable-Diffusion.git
cd Dreambooth-Stable-Diffusion
conda env create -f environment.yaml
conda activate ldmAhora tenemos que instalar las librerías necesarias para entrenar el modelo generado con nuestro «concepto de entrada», vayamos paso a paso:
pip install -qq git+https://github.com/huggingface/diffusers.git accelerate tensorboard transformers ftfy gradio
pip install -qq "ipywidgets>=7,<8"
pip install -qq bitsandbytesEn mi Github he dejado los scripts necesarios para entrenar al modelo y posteriormente generar imágenes utilizando el resultante. Tienes que subirlos al servidor utilizando el cliente de GCloud:
gcloud compute scp SCRIPT NOMBRE_INSTANCIA:~/Dreambooth-Stable-Diffusion/Un detalle a tener en cuenta son las clases de imágenes, vienen a ser el tipo de elemento que representa nuestro concepto, es decir, si queremos que Stable Diffusion genere imágenes en la que aparezcamos nosotros la clase viene a ser una persona (person), si quisiéramos que apareciera nuestro perro pondríamos dog, como si fuera una etiqueta.
Hay una carpeta llamada class_images que contiene imágenes de ejemplo de nuestra clase, fácil, de perros si vamos a añadir uno, de personas parecidas si es el caso, pero no imágenes del concepto en sí mismo. Podemos añadirlas o dejar que la IA las genere por nosotros, de ser el último caso tenemos que cambiar el texto indicado en el prior_preservation_class_prompt del script de entrenamiento.
Entrenamiento
En el script de entrenamiento hay que modificar unos detalles:
- URL de las imágenes: El script recoge las imágenes de internet, aquí tienes que sustituir las direcciones que hay por aquellas donde tengas las tuyas, si no las tienes en algún servicio de internet que te permita darles visibilidad pública aunque sea temporalmente puedes crearte una cuenta en Google Drive, OneDrive, Dropbox, iCloud, etc. Puedes añadir las que quieras teniendo en cuenta que esto afectará al consumo de recursos y será más fácil que se llene la memoria gráfica.
- Configuración del prompt personalizado:
instance_prompt: La palabra que le indicará a Stable Diffusion que la imagen generada debe contener el concepto (imagen) que le introducimos, nuestra persona en este caso, podemos poner nuestro nombre o algo parecido, en el ejemplo le hemos llamadomyprompt.prior_preservation_class_prompt: Aquí se debe escribir un texto que servirá para generar las imágenes de ejemplo en caso de no haber añadido ninguna. La IA generará imágenes basándose en él. Si le indicamos que vamos a utilizar más imágenes de ejemplo de las que añadimos a la carpeta las generará automáticamente hasta cubrir la diferencia.num_class_images: El número de imágenes de ejemplo que se utilizarán para el entrenamiento.sample_batch_size: Cantidad de nuestras imágenes que se utilizarán (las que están en las url). Para mi caso utilicé alrededor de 15 fotos mías, en teoría con tres o cuatro es suficiente.
Estos scripts no son perfectos, pueden tener errores y son básicamente recopilaciones o adaptaciones de otros encontrados en internet, pero a mi me han funcionado para generar al menos una aproximación de lo que se puede ver en el vídeo de @DotCsv, estas son las fuentes principales:
- El Colab de la gente de Dreambooth compartido por @DotCsv para el entrenamiento.
- Un script de generación de imágenes utilizando un modelo propio encontrado en internet del que no consigo el enlace, cuando lo recupere actualizaré la entrada.
El resultado que obtendremos no es perfecto, en realidad sólo un pequeño porcentaje de las imágenes generadas nos identificarán perfectamente, habrá aproximaciones, habrá parecidos y sí, habrá casi perfecciones pero son pocas (al menos en mi caso). Cuantas más y mejores imágenes utilices para entrenar al modelo y cuánto mejor sea la configuración utilizada mejores serán los resultados pero también más elevado el coste.
Yo aquí te planteo una opción más o menos económica con unos resultados bastante decentes.
¿Quieres verlos? Ya no queda nada
Necesitamos una «copia» de la versión pre entrenada de Stable Diffusion que el script se encargará de descargar de Hugging Face, simplemente nos creamos una cuenta desde su web e iniciamos sesión desde la consola de la instancia virtual:
pip install huggingface_hub
huggingface-cli loginNos solicitará un token que podemos obtener en nuestro perfil. A la hora de crearlo tenemos que darle permisos de escritura si vamos a guardarlo en la nube, después instalamos y configuramos accelerate con:
pip install accelerate
accelerate configRespondemos las preguntas que nos formula en base a las configuraciones elegidas durante el proceso de creación de la instancia en GCP.
Una vez esté terminado estamos preparados para realizar el entrenamiento, con nuestras imágenes en la lista de url, las de ejemplo en la carpeta class_images y los parámetros del script de instalación modificados procedemos a lanzarlo:
python sd-training-train.py Empezará a descargar nuestras imágenes y a generar las de ejemplo si tuviera que crear alguna y tras unos minutos terminará dejándonos en la carpeta dreambooth-concept el modelo entrenado con nuestro nuevo concepto listo para poder utilizar.
¿Cómo?
Generación de imágenes con nuestro concepto integrado
Con el script de generación de imágenes, eso sí hay que tener en cuenta que si cambiamos en el script de entrenamiento la carpeta de destino de nuestro modelo también hay que modificarlo aquí.
Si no lo hemos tocado basta con cambiar:
sample_num: Número de imágenes a generarprompt: El texto que describe las condiciones de las imágenes que se generarán, recuerda poner el que pusiste al entrenar al modelo para que utilice tu concepto.guidance_scaleyseedson parámetros que modifican parte de las imágenes generadas, ahí ya queda a tu disposición jugar con ello para encontrar tus mejores creaciones, los mismos parámetros no van siempre bien con el mismo tipo de imágenes y viceversa, prueba.
Lo ejecutamos y dejamos hacer su trabajo:
python sd-training-generate.pyTras unos segundos almacenará las creaciones en la carpeta outputs que descargaremos utilizando el protocolo SCP con la herramienta proporcionada por el cliente de GCloud:
gcloud compute scp --recurse NOMBRE_INSTANCIA:~/Dreambooth-Stable-Diffusion/outputs ~/Descargas/Con suerte habremos generado imágenes nuestras en situaciones que nunca hubiéramos imaginado, estilos sorprendentes o creaciones fantásticas, todo es probar y mejorar,
¿Hasta dónde eres capaz de llegar?
Yo lo he probado, he cometido errores y he tenido que aprender mucho, he intentado juntar varias cosas sin éxito hasta dar con «la fórmula final», este es el resultado.


Si le preguntas a un conocido/amigo mio te dirá que hay una especialmente destacable.
¿Sin conocerme sabrías decirme cuál?
Como puedes ver con un gasto no muy elevado podemos hacer uso de los servicios de Google para entrenar nuestros propios modelos de Stable Diffusion con los que luego generar creaciones de lo más originales que podremos utilizar para crear nuevos productos, ilustrar historias, películas, diseñar ropa, personajes de videojuegos y lo que se nos ocurra.
Lo que puedo asegurarte es que al final te sorprenderás, todo lo que habrás aprendido al terminar, las posibilidades que se te irán ocurriendo durante el camino, las herramientas que conocerás y los resultados, que aun siendo mejores o peores seguro te harán sentir satisfecho o satisfecha del proceso.
Te animo a intentarlo, por mucha palabra rara que se pueda ver y por muy largo que parezca ya está casi todo hecho para poder reproducirlo con cuatro cosas, si tienes algún problema no dudes en dejarlo en los comentarios que seguro entre todos podemos ayudarnos.
Te dejo documentados también los errores con los que me he ido encontrando y como solucionarlos. Como decía antes este proyecto no es definitivo, no soy experto en algoritmos de IA, simplemente he recopilado la información disponible y aplicado mis conocimientos para generar una versión primitiva que puede ir mejorándose para obtener resultados más satisfactorios.
Iré actualizando el artículo con las nuevas mejoras que vaya encontrando y si has encontrado algún fallo o quieres proponer alguna mejora del proceso será más que bienvenida, de esta forma todos nos beneficiamos.
Errores comunes
Durante el proceso pueden surgir algunos errores, quizá alguno de ellos esté en la lista:
- No se puede acceder al fichero
config.jsonó advertencia de incompatibilidad con la tarjeta gráfica: Esto es porque PyTorch no puede acceder a la subcarpeta con la configuración necesaria, probablemente sea porque no está actualizada o no es del todo compatible con tu tarjeta gráfica, para instalar la correcta obtén el comando de instalación correspondiente al entorno de tu instancia virtual desde su página. Para saber la versión de CUDA ejecutamosnvidia-smiy para evitar conflictos entre versiones lo desinstalamos primero con:
pip uninstall torch- Error
CUDA Out of memory: Puede pasar que modificando los parámetros del script de entrenamiento hayamos asignado demasiados recursos causando que la memoria se llene, de ser así necesitamos liberar la carga ya sea quitando algunas imágenes, reduciendo su tamaño, cambiando la cantidad de recursos utilizados, etc. O también puedes aumentar las capacidades de tu instancia asumiendo los costes que pueda conllevar. - Error de importación de
GLIBCXX: Activamos entorno decondade LDM:
conda activate ldmReferencia
Enlaces con documentación relacionada:
- Ajuste de Dreambooth para una difusión estable mediante difusores: Google Colab
- Paper de Stable Diffusion: Google Colab
- Stable Diffusion: Stability.ai
- Dreambooth: Github
- Cómo ejecutar Stable Diffusion en GCP: TowardsDataScience
Desarrollador de software, informático, emprendedor y entusiasta por la tecnología desde tiempos inmemoriales. Inquieto por defecto, curioso por naturaleza, trato de entender el mundo y mejorarlo utilizando la tecnología como herramienta.
1 Comment