
Despliegue de la arquitectura completa para aplicaciones con Hasura, Docker y Flutter
GraphQL es un lenguaje de consultas y manipulación de datos de código abierto para datos nuevos o existentes. Fue desarrollado inicialmente por Facebook (Meta) en 2012 antes de hacerse de código abierto en 2015.
Hasura nos permite construir APIs modernas basadas en GraphQL de forma rápida y fácil. Nos proporciona también una serie de herramientas por defecto que nos facilitarán tanto el proceso de creación como el de gestión y despliegue de la infraestructura. Puede ejecutarse en un servidor propio (auto alojado) o en la nube.
Docker es una plataforma de código abierto que permite el despliegue de aplicaciones dentro de contenedores virtuales, lo utilizaremos para ejecutar Hasura y PostgreSQL como base de datos para las pruebas.
Descarga, instalación y ejecución de Docker
Lo primero es acceder a su pagina oficial y descargar e instalar la versión correspondiente a nuestro sistema operativo. Una vez instalado lo ejecutamos y comprobamos que se ha procesado correctamente con:
docker Los ficheros docker-compose son ficheros de configuración que nos permiten definir y ejecutar aplicaciones Docker. En nuestro caso vamos a utilizar un fichero de configuración provisto por Hasura para desplegarlo junto a PostgreSQL, comprobamos que el comando funcione correctamente también:
docker-composeFichero docker-compose.yaml y virtualización de Hasura junto a PostgreSQL
En la documentación oficial de Hasura tenemos los pasos a seguir para desplegarlo utilizando Docker, básicamente hay que copiar el fichero docker-compose.yaml de su Github en nuestro PC para lanzarlo con el comando docker-compose up -d.
Con docker ps podemos comprobar que ambos contenedores se están ejecutando sin problemas además de ver toda la información relativa a los mismos, estado, puertos, imágenes, volúmenes, etc.
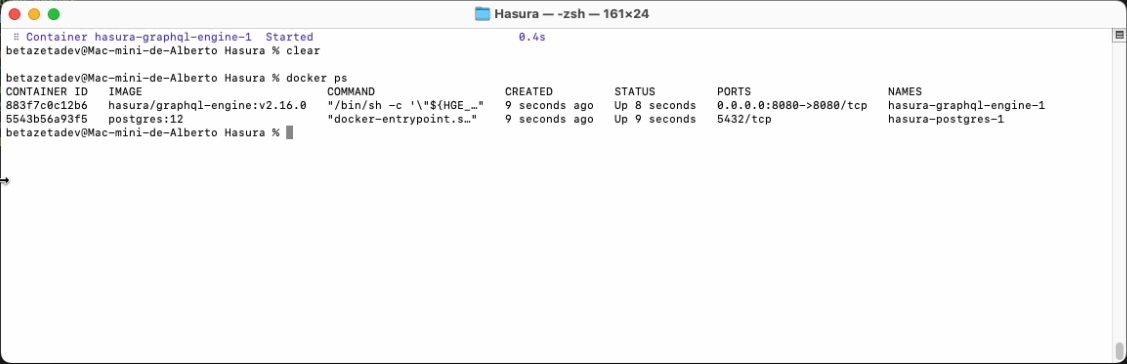
Una vez desplegado podemos acceder a la dirección localhost:8080 desde nuestro navegador web.

Arriba tenemos diferentes pestañas:
API: Una interfaz gráfica para realizar consultas a nuestra base de datos utilizando la sintaxis de GraphQL.Data: Para gestionar nuestra base de datos, relaciones, permisos, etc.Actions: Llamadas a una tercera API externa.Remote schemas: Conexión con otras bases de datos.Events: Gestión de eventos de nuestra base de datos como inserciones, actualizaciones o borrados, los clásicos
triggers.Monitoring: Monitorización de nuestra API, accesos, errores y demás.
Creación de la base de datos y acceso a los mismos
Ahora que ya tenemos Hasura corriendo es hora de conectar nuestra base de datos y crear alguna tabla para insertar datos y poder realizar consultas desde su interfaz gráfica. Desde la pestaña Data podemos crear una nueva base de datos, en nuestro caso la llamaremos testdb y la conectaremos utilizando la URL de conexión configurada en el fichero docker-compose.yaml del principio:
postgres://postgres:postgrespassword@postgres:5432/postgres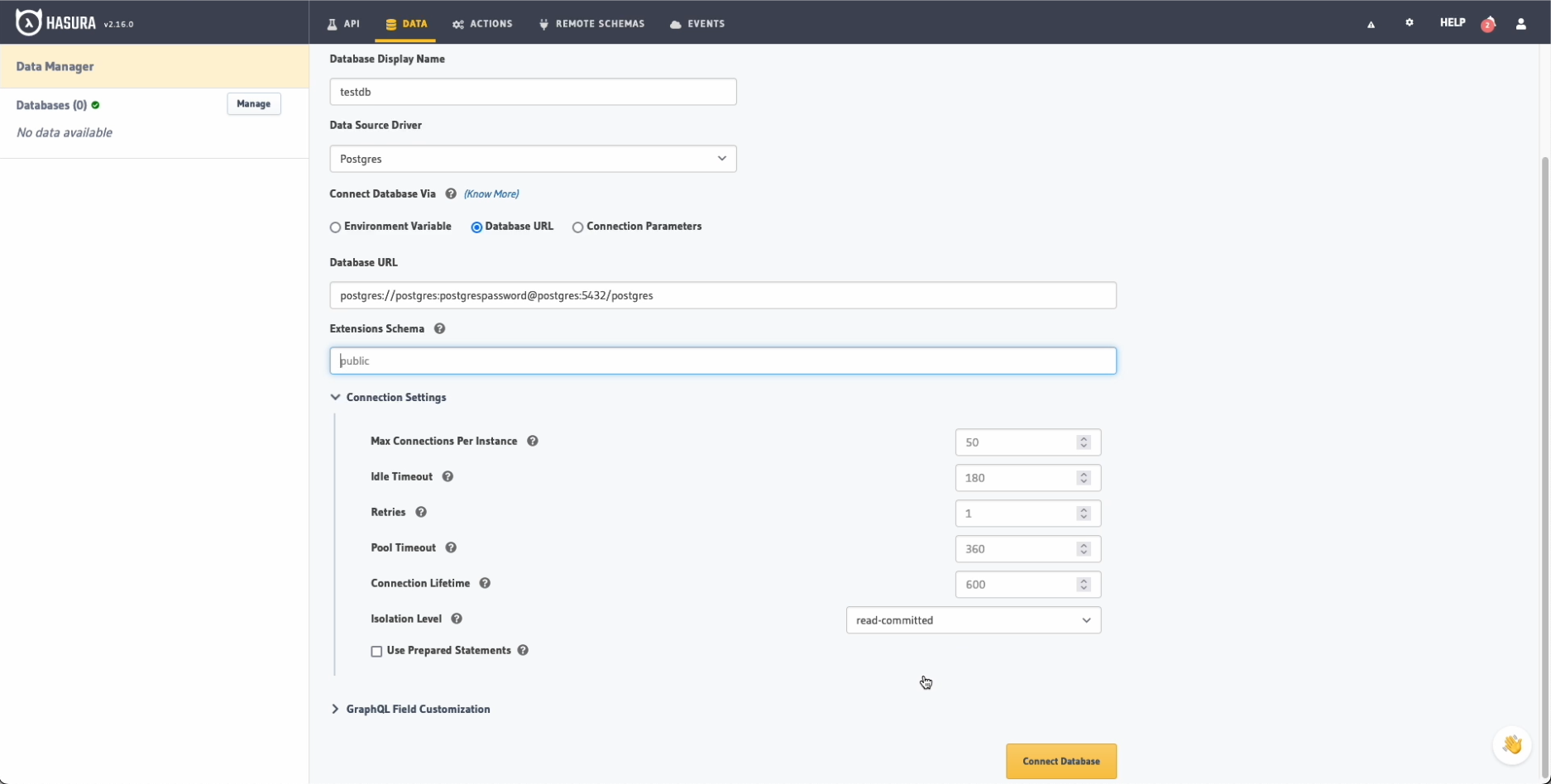
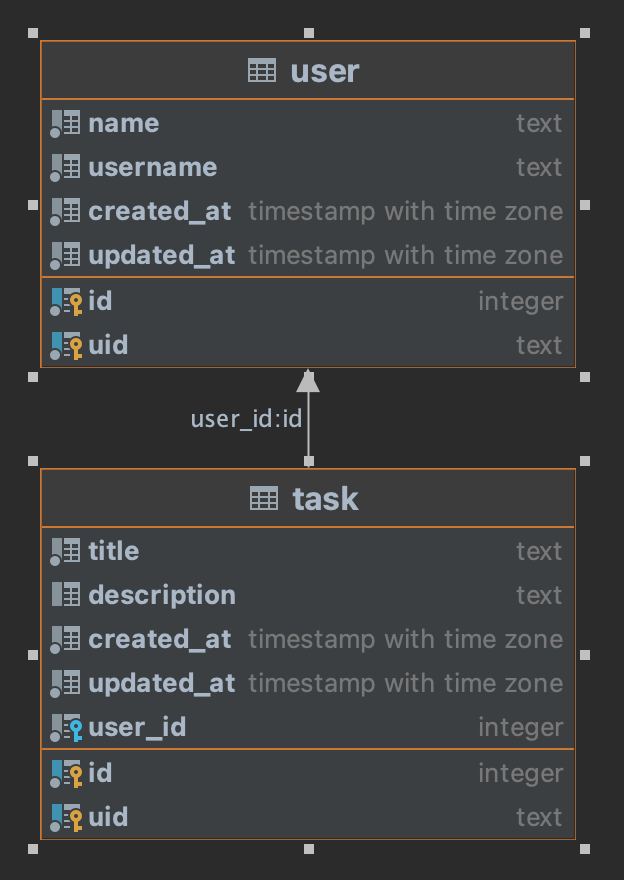
En este ejemplo crearemos una base de datos con dos tablas user y task con la única peculiaridad de que la tabla task está relacionada con la de user mediante el campo user_id para poder saber a quién pertenece cada tarea y jugar un poco con los filtrados y las diferentes formas de recoger los datos según el caso de uso.
Usando la propia interfaz de usuario de Hasura podemos insertar nuevos datos, la pestaña Insert row dentro de Data nos permite hacerlo fácilmente y rápido. Podríamos necesitar crear un usuario primero para poder crear tareas para él si ya hemos creado las restricciones de la relación.
Tras insertar nuestros datos podemos entrar en la pestaña API para empezar a hacer consultas, en el ejemplo yo sólo he creado un usuario con dos tareas asignadas para las pruebas pero lógicamente cuánto mayor sea la cantidad de datos más interesantes y útiles serán las consultas que podamos realizar.
Podemos consultar todas las tareas:
query AllTasks {
task {
id
title
description
}
}Podemos consultar todas las tareas con el usuario al que pertenece cada una:
query AllTasksWithUser {
task {
id
title
description
user {
id
name
}
}
}O aquellas tareas con un título igual a un texto introducido:
query TasksByTitle {
task(where: {title: {_similar: "Task title"}}) {
id
title
description
user {
id
name
}
}
}Pero no sólo eso, además también podemos ordenarlas por fecha de creación (descendiente en este caso):
query TasksByTitleOrderDesc {
task(order_by: {created_at: desc}) {
id
title
description
user {
id
name
}
}
}Si tenemos indexada la relación entre usuario y tarea (pulsando en Track a la relación entre ambos dentro de Data) podemos directamente recoger a través de un usuario todas sus notas en vez de tener que obtenerlos de cada nota individualmente:
query UsersTasks {
user {
id
name
tasks {
id
title
description
}
}
}En los ejemplos se puede observar que la diferencia con las clásicas API REST es que en este caso quién determina los datos a obtener es el propio cliente y no el servidor, mientras que REST se basa en peticiones estáticas predefinidas por el servidor, GraphQL ofrece por defecto los datos que pueden llegar a ser necesarios y el cliente solicitará aquellos que realmente necesite.
Esto es muy útil para optimizar el tráfico de datos y no sobrecargar la red con información que no se va a utilizar, puede que para un menú sólo necesitemos el título de una tarea o puede que necesitemos mostrar la información completa, solicitaremos en cada caso los datos estrictamente necesarios, es decisión del cliente.
Como todo, hacerlo de esta forma tiene sus convenientes e inconvenientes, es cuestión de conocerlo y tener alternativas con las que poder facilitarnos el trabajo y adaptarnos a las necesidades de cada proyecto.
Puedes ver todo el proceso en vídeo desde nuestro canal de Youtube.
Hemos visto cómo crear una API GraphQL utilizando Hasura y Docker, añadido y consultado datos en cuestión de minutos. Para un proyecto en el que sea necesario tener un producto mínimo viable (MVP) de forma rápida.
Ahora veremos en profundidad las diferentes operaciones (Query, Mutation, Subscription) que GraphQL nos ofrece para poder gestionar nuestros datos a través de la API. En su especificación tienes toda la información necesaria.
Principalmente GraphQL especifica tres clases de operaciones:
- Query: Solicitar datos.
- Mutation: Crear, actualizar o eliminar.
- Subscription: Gestión en tiempo real.
GraphQL
Query
Las Query (consulta) son la forma más común de interacción con una API GraphQL. Como una consulta de las clásicas bases de datos nos permite obtener información del servidor, en este caso a través de la API previamente expuesta en condiciones de seguridad. Hasura nos permite gestionar roles y permisos para limitar la información que se expone pero eso lo veremos más adelante.
Podemos por ejemplo obtener los id (ID interno), title (Título) y created_at (Fecha de creación) de todas las tareas con la Query:
SOLICITUD
query AllTasksQuery{
task {
id
title
created_at
}
}RESPUESTA
{
"data": {
"task": [
{
"id": 8,
"title": "Limpiar la casa",
"created_at": "2022-11-30T11:20:46.148+00:00"
},
{
"id": 12,
"title": "Crear una lista de tareas",
"created_at": "2022-12-13T00:31:17.686201+00:00"
},
{
"id": 10,
"title": "Escribir un informe",
"created_at": "2022-07-17T00:10:33.29+00:00"
},
...
]
}
}También podemos establecer un límite de dos tareas con la opción limit:
SOLICITUD
query AllTasksQuery{
task(limit: 2) {
id
title
created_at
}
}RESPUESTA
{
"data": {
"task": [
{
"id": 8,
"title": "Limpiar la casa",
"created_at": "2022-11-30T11:20:46.148+00:00"
},
{
"id": 12,
"title": "Crear una lista de tareas",
"created_at": "2022-12-13T00:31:17.686201+00:00"
}
]
}
}Nos devuelve las dos primeras tareas de la base de datos, consulta que podemos combinar con una operación de ordenación por fecha.
SOLICITUD
query LimitedTasksQuery{
task(limit: 2, order_by: {created_at: desc}) {
id
title
created_at
}
}RESPUESTA
{
"data": {
"task": [
{
"id": 19,
"title": "Comprar polvorones",
"created_at": "2022-12-13T01:29:53.106341+00:00"
},
{
"id": 17,
"title": "Visitar a la familia",
"created_at": "2022-12-13T01:28:04.622421+00:00"
}
]
}
}El parámetro where nos permite filtrar los resultados de la consulta, en este caso por ejemplo recibiremos únicamente aquellas tareas creadas después del 1 de diciembre de 2022:
SOLICITUD
query FilteredTasksQuery{
task(where: {created_at: {_gt: "2022-12-01"}}) {
id
title
created_at
}
}RESPUESTA
{
"data": {
"task": [
{
"id": 12,
"title": "Crear una lista de tareas",
"created_at": "2022-12-13T00:31:17.686201+00:00"
},
{
"id": 13,
"title": "Bajar al perro",
"created_at": "2022-12-13T01:13:49.136216+00:00"
},
{
"id": 14,
"title": "Hacer deporte",
"created_at": "2022-12-13T01:16:35.274353+00:00"
},
...
]
}
}Cada una de las funcionalidades ofrecidas por GraphQL pueden ser combinadas entre sí para ajustar la respuesta del servidor a las necesidades del cliente, en este caso le añadimos una ordenación por fecha de creación ascendente:
SOLICITUD
query FilteredTasksQuery{
task(order_by: {created_at: asc}, where: {created_at: {_gt: "2022-12-01"}}) {
id
title
created_at
}
}RESPUESTA
{
"data": {
"task": [
{
"id": 7,
"title": "Planificar una fiesta",
"created_at": "2022-12-03T05:45:22.096+00:00"
},
{
"id": 5,
"title": "Crear un presupuesto",
"created_at": "2022-12-06T10:28:59.551+00:00"
},
{
"id": 1,
"title": "Hacer una lista de la compra",
"created_at": "2022-12-09T01:37:55.790089+00:00"
},
...
]
}
}Podemos también filtrar variables por texto por ejemplo recogiendo todas las tareas cuyo usuario de creación coincida con un nombre específico:
SOLICITUD
query FilteredTasksQuery{
task(where: {user: {name: {_eq: "Alfred"}}}) {
user {
name
}
id
title
created_at
}
}RESPUESTA
{
"data": {
"task": [
{
"user": {
"name": "Alfred"
},
"id": 12,
"title": "Crear una lista de tareas",
"created_at": "2022-12-13T00:31:17.686201+00:00"
},
{
"user": {
"name": "Alfred"
},
"id": 7,
"title": "Planificar una fiesta",
"created_at": "2022-12-03T05:45:22.096+00:00"
},
{
"user": {
"name": "Alfred"
},
"id": 5,
"title": "Crear un presupuesto",
"created_at": "2022-12-06T10:28:59.551+00:00"
},
...
]
}
}Hasta ahora hemos estado introduciendo los datos directamente en la consulta pero también tenemos la posibilidad de utilizar variables tanto desde el cliente como en la propia interfaz de Hasura GraphiQL si pulsamos el símbolo del dólar al lado del parámetro en cuestión.
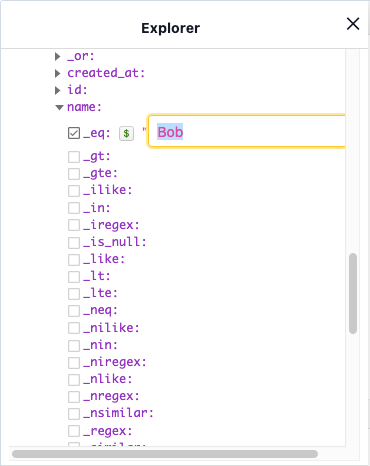
SOLICITUD
query FilteredTasksQuery($userName: String!){
task(where: {user: {name: {_eq: $userName}}}) {
user {
name
}
id
title
created_at
}
}En el recuadro inferior Query Variables podemos introducir en formato JSON las variables que vayamos a utilizar en la consulta:
VARIABLES
{
"userName": "Alfred"
}RESPUESTA
{
"data": {
"task": [
{
"user": {
"name": "Alfred"
},
"id": 12,
"title": "Crear una lista de tareas",
"created_at": "2022-12-13T00:31:17.686201+00:00"
},
{
"user": {
"name": "Alfred"
},
"id": 7,
"title": "Planificar una fiesta",
"created_at": "2022-12-03T05:45:22.096+00:00"
},
{
"user": {
"name": "Alfred"
},
"id": 5,
"title": "Crear un presupuesto",
"created_at": "2022-12-06T10:28:59.551+00:00"
},
...
]
}
}También podemos obtener todas aquellas tareas que contengan la palabra casa en su título:
SOLICITUD
query FilteredTasksQuery{
task(where: {title: {_like: "%casa%"}}) {
id
title
created_at
}
}RESPUESTA
{
"data": {
"task": [
{
"id": 8,
"title": "Limpiar la casa",
"created_at": "2022-11-30T11:20:46.148+00:00"
}
]
}
}El offset nos permite saltarnos un número de resultados, por ejemplo para obtener las tareas empezando a partir de la tercera nos saltamos las dos primeras:
SOLICITUD
query FilteredTasksQuery{
task(offset: 2) {
id
title
created_at
}
}RESPUESTA
{
"data": {
"task": [
{
"id": 10,
"title": "Escribir un informe",
"created_at": "2022-07-17T00:10:33.29+00:00"
},
{
"id": 13,
"title": "Bajar al perro",
"created_at": "2022-12-13T01:13:49.136216+00:00"
},
{
"id": 14,
"title": "Hacer deporte",
"created_at": "2022-12-13T01:16:35.274353+00:00"
},
...
]
}
}Mutation
En GraphQL una Mutation es una operación que permite modificar los datos del servidor. Es similar a una consulta pero en lugar de obtener datos (más allá de los recién creados), realiza una acción que modifica algún aspecto del estado del servidor.
Para agregar un nuevo usuario o una tarea podemos utilizar las siguientes Mutation. En esta primera llamada añadimos un nuevo usuario introduciendo los parámetros directamente en la consulta:
MODIFICACION
mutation InsertUserMutation {
insert_user(objects: {
uid: "25d4c7b0-1b5a-4b9e-8c5a-2c7f3a7478e9",
username: "monique",
name: "Monique"}) {
affected_rows
returning {
id
name
}
}
}RESPUESTA
{
"data": {
"insert_user": {
"affected_rows": 1,
"returning": [
{
"id": 10,
"name": "Monique"
}
]
}
}
}Y esta otra para insertar una nueva tarea utilizando variables. En nuestro ejemplo la clase task_insert_input es generada por Hasura automáticamente y define los campos que podemos utilizar para insertar una nueva tarea.
MODIFICACION
mutation InsertTaskMutation($objects: [task_insert_input!] = {}) {
insert_task(objects: $objects) {
affected_rows
returning {
id
title
created_at
}
}
}Pasándole de nuevo los parámetros mediante variables en formato JSON:
VARIABLES
{
"objects": {
"title": "Escribir un artículo",
"uid": "486a4252-6576-45d3-bc9a-1d6f0388b581",
"user_id": 6
}
}RESPUESTA
{
"data": {
"insert_task": {
"affected_rows": 1,
"returning": [
{
"id": 21,
"title": "Escribir un artículo",
"created_at": "2022-12-20T22:30:23.434237+00:00"
}
]
}
}
}En el panel derecho de Hasura llamado Documentation Explorer encontramos la documentación generada para ver los campos requeridos por nuestras consultas, por ejemplo la clase task_insert_input del ejemplo:
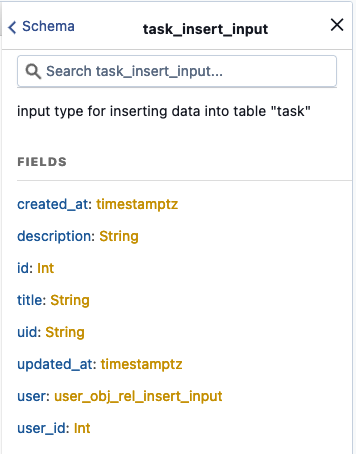
Subscription
Las Subscription nos sirven para comunicarnos en tiempo real y de forma bidireccional con el servidor, actualizando la información en los clientes inmediatamente. Utiliza la tecnología WebSockets para mantener un canal abierto y así poder comunicarse sin tener que iniciar de nuevo la conexión.
Su uso excesivo puede llegar a provocar un gran consumo de recursos y dependiendo la casuística del proyecto pueden no ser necesarias o añadir complejidad a la implementación. Siguiendo con el ejemplo, podríamos crear una subscripción para tener la lista de usuarios actualizados en tiempo real:
subscription AllUsersSubscription {
user {
id
name
}
}También podemos utilizar los filtrados y ordenaciones como en este ejemplo para obtener las tareas de todos los usuarios con nombre Bob:
subscription BobTasksSubscription {
task(where: {user: {name: {_eq: "Bob"}}}) {
id
title
created_at
}
}Para ver los resultados de las subscripciones en vivo te recomiendo el vídeo de un poco más adelante.
Los Fragment no son operaciones como tal pero no está de más mencionarlos ya que suelen acompañar a estas operaciones porque nos permiten reutilizar partes de las consultas y crear una especie de plantillas para no repetir código y simplificar así la organización.
Administración de Hasura a fondo
Estas son las operaciones básicas que podemos realizar con GraphQL, para ver los Fragment, tipos de datos personalizados y otros detalles todo está definido a la perfección en la especificación oficial.
Ahora vamos a ver las diferentes opciones que Hasura nos proporciona por defecto para gestionar la base de datos, ejecutar tareas en el lado del servidor o conectar con servicios externos.
Para este ejemplo vamos a descargar una base de datos ya creada con datos de muestra, concretamente la que contiene información de un negocio de alquiler de películas llamada Pagila.
Simplemente tenemos que importar el esquema y los datos de ejemplo con psql. Después podemos crear la conexión a la base de datos virtualizada desde el panel de Hasura como vimos anteriormente.
En el fichero docker-compose tenemos que añadir la cláusula ports al apartado de postgres para poder conectar desde fuera del contenedor virtualizado:
Panel de administración
version: '3.6'
services:
postgres:
image: postgres:12
ports:
- "5432:5432"
volumes:
...Explorador de API
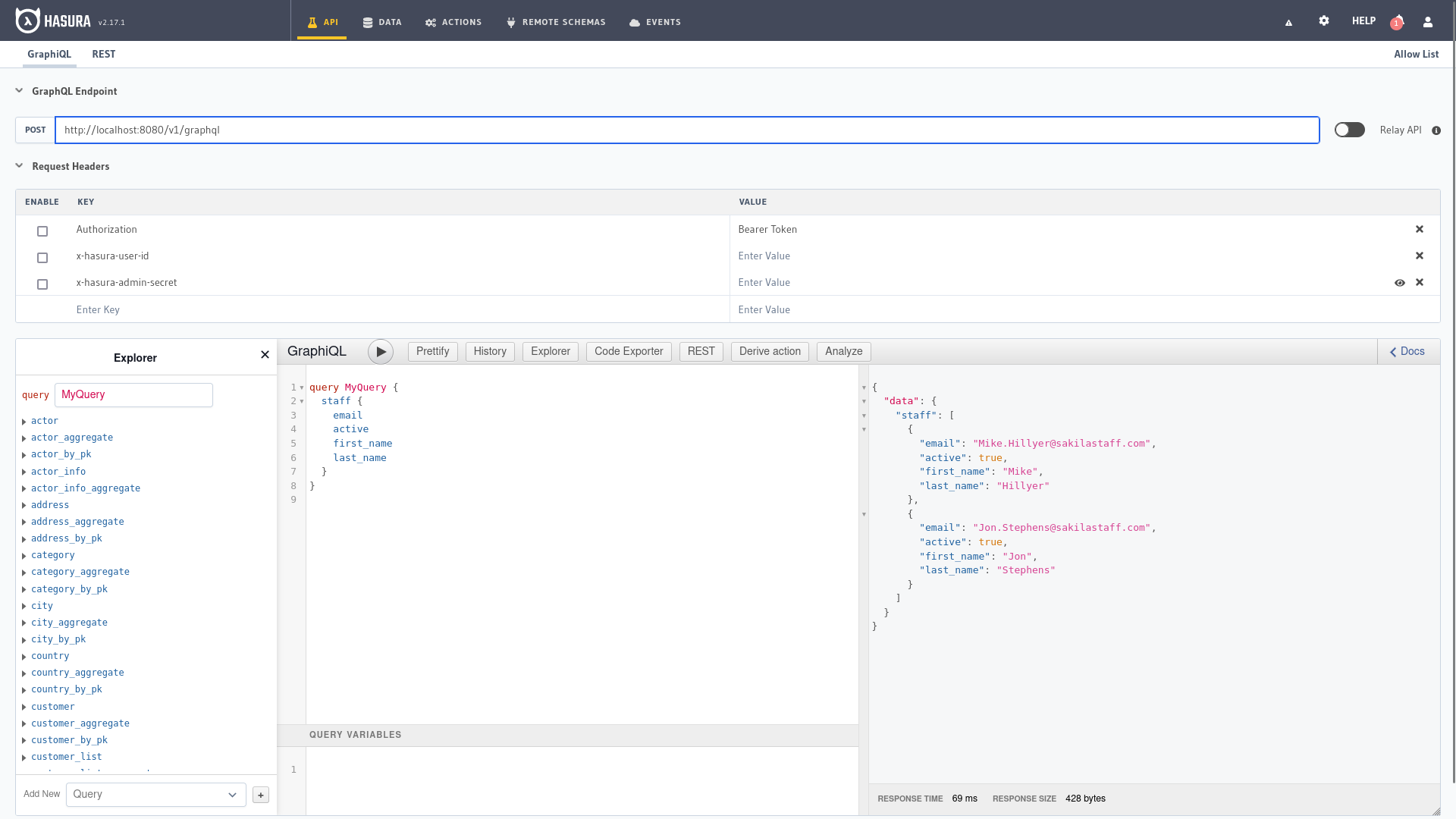
Es la primera pantalla que nos encontramos al entrar en el panel de administración de Hasura y en ella tenemos varias partes bien diferenciadas, en la parte superior está la dirección URL de nuestro endpoint y los parámetros incluidos en la cabecera a la petición de la API.
A la izquierda el explorador para navegar por las diferentes entidades, GraphiQL nos permite realizar consultas y la documentación dónde consultar los diferentes parámetros y opciones disponibles a la derecha. Abajo escribiríamos los valores de las variables en formato JSON si se realizan peticiones con variables en GraphiQL.
Ya hemos visto múltiples ejemplos que podemos trasladar y adaptar para ejecutar directamente desde aquí o podemos utilizar el explorador para construir nuestra consulta con las diferentes opciones de filtrado, selección y ordenación del mismo.
Datos
Nada más acceder a la segunda pestaña nos encontramos con un administrador de datos a la izquierda y a la derecha las tablas de las que se está haciendo seguimiento. Abajo a la izquierda hay un botón que nos abrirá una ventana para ejecutar consultas SQL de forma manual.
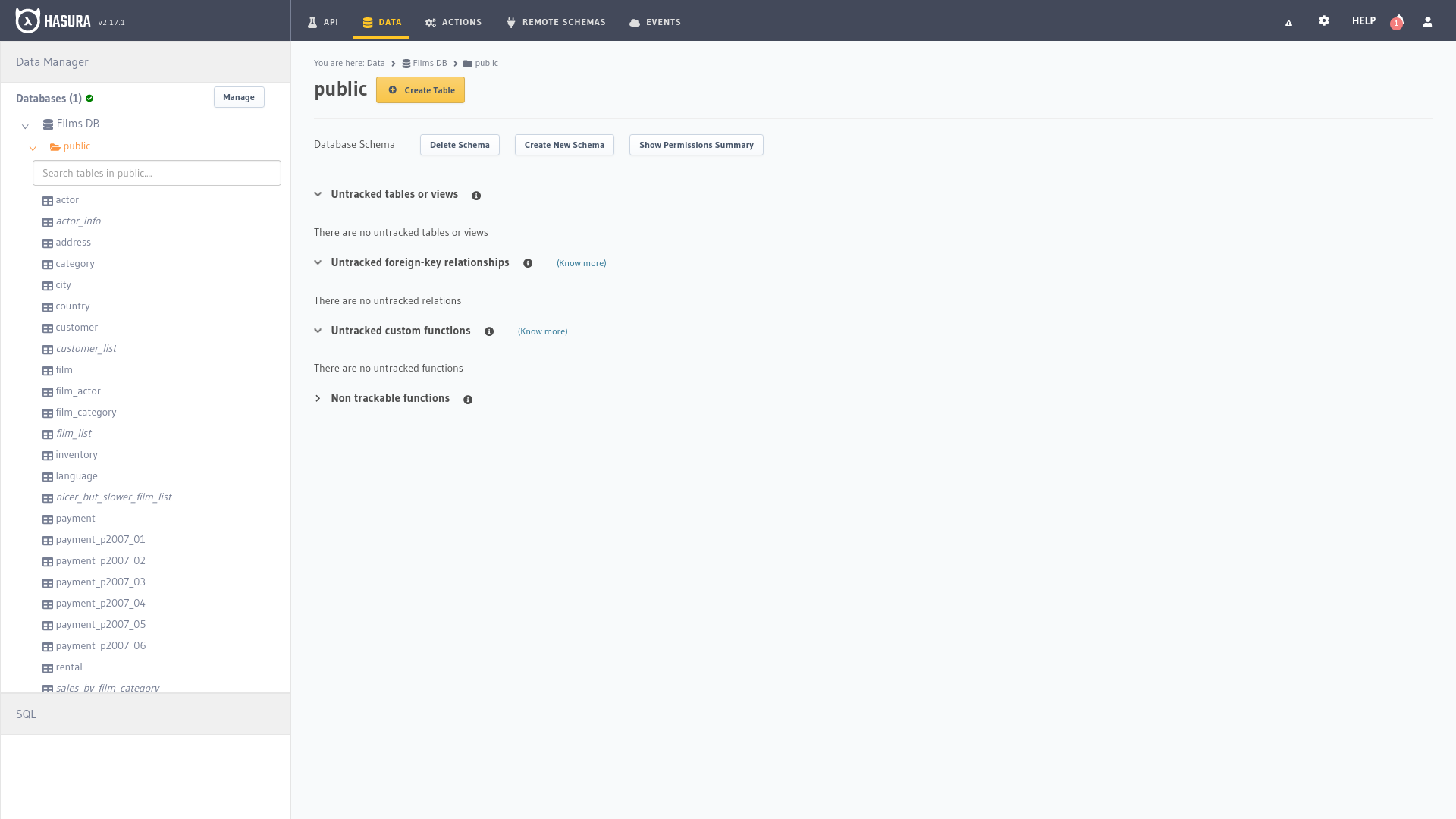
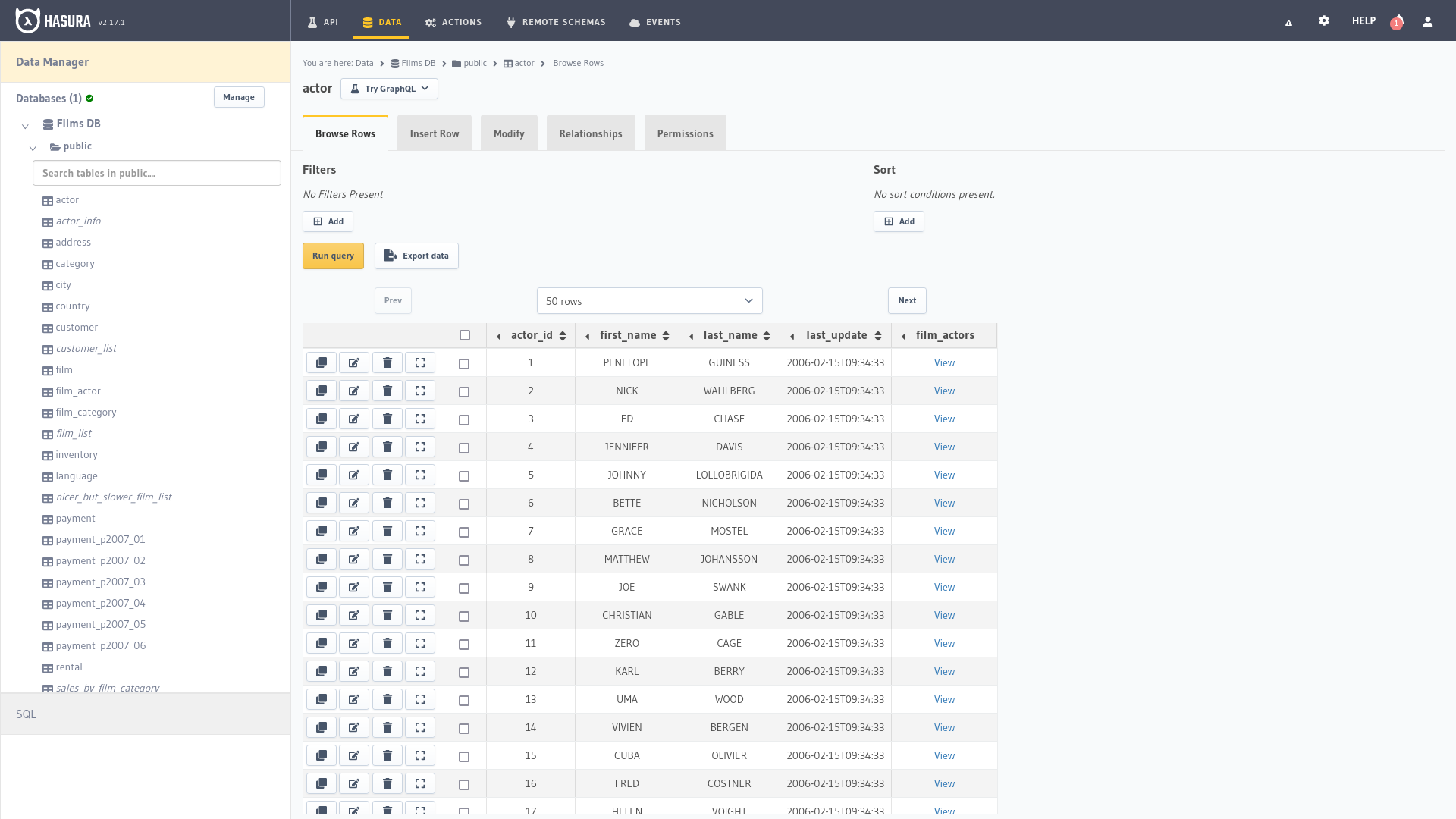
Explorar filas
Al seleccionar alguna de las entidades en el administrador de la izquierda se nos mostrarán los registros que la tabla contiene además de permitirnos añadir nuevas filas o modificar las existentes, las relaciones entre las entidades y los permisos de acceso a los datos a través de la API.
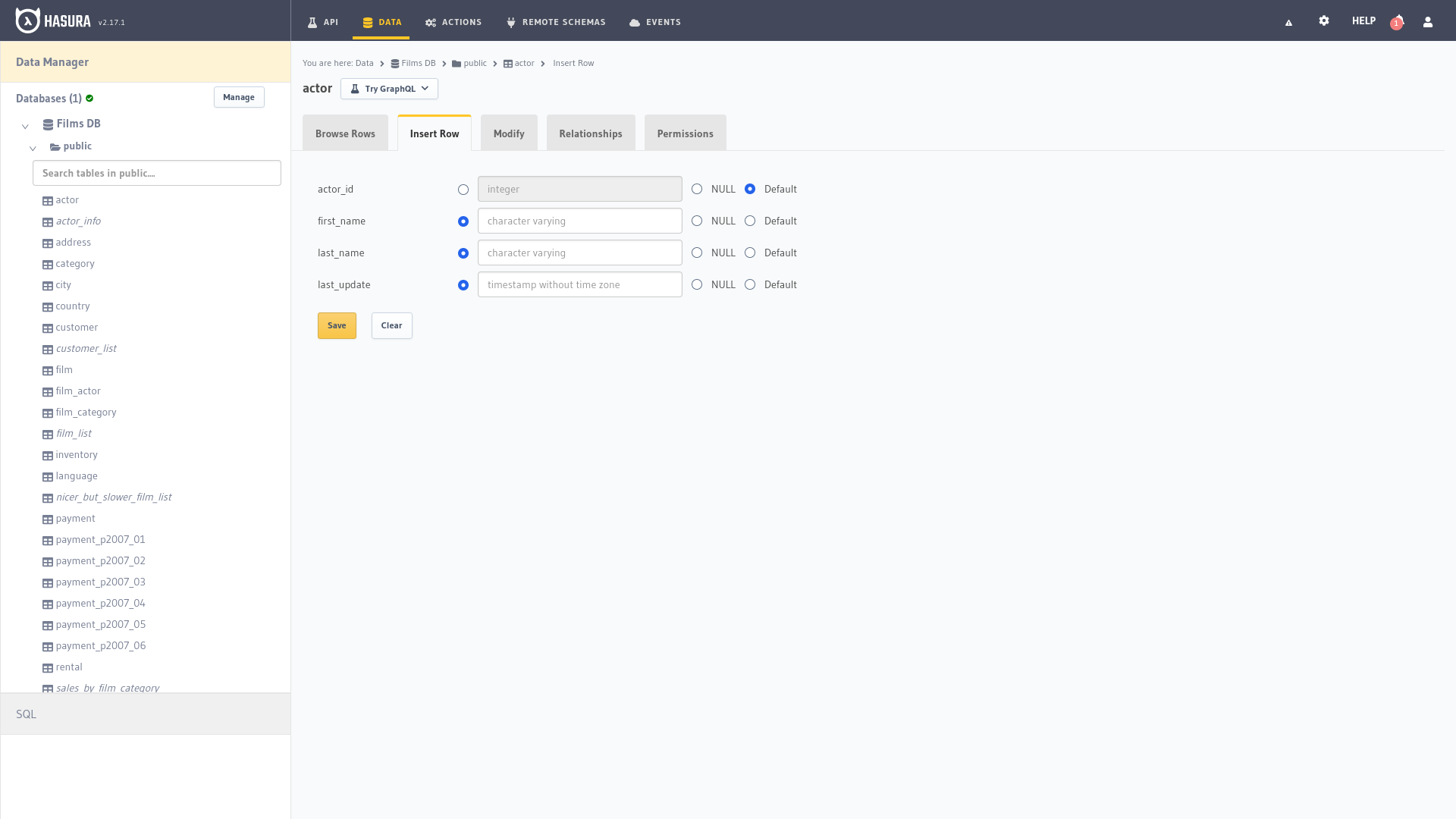
Insertar fila
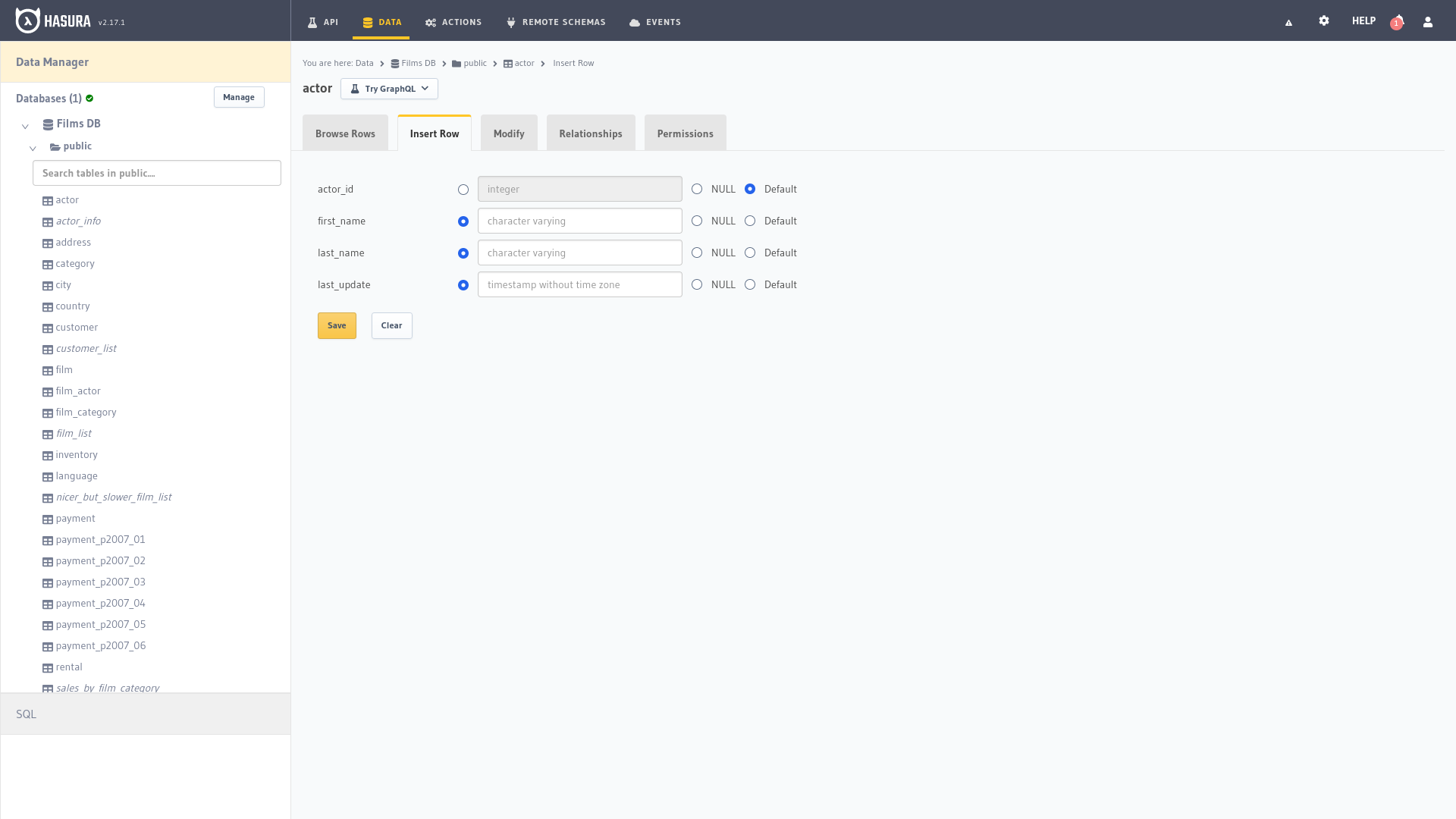
La opción Insert en el panel de administración de Hasura es una característica esencial que permite a los usuarios agregar nuevos registros a las tablas de la base de datos de manera rápida y sencilla. Esta funcionalidad proporciona una interfaz gráfica intuitiva para insertar datos, eliminando la necesidad de escribir consultas SQL manuales y simplificando el proceso de inserción de registros en la base de datos.
Al seleccionar una tabla específica en el panel de administración de Hasura se accede a la pestaña Insert Row (Insertar fila), dónde se pueden ingresar valores para cada campo de la tabla. La interfaz presenta cada columna junto con su tipo de datos, facilitando la inserción de datos coherentes y adecuados para cada campo. Además, Hasura proporciona opciones para establecer valores predeterminados o nulos en campos que lo permitan, lo que facilita la gestión de los registros.
Modificar
La pestaña Modify nos permite cambiar los parámetros de las diferentes columnas de la tabla así cómo añadir nuevas, los triggers, las restricciones, índices y demás, también nos permite establecer la tabla como un tipo enum para datos fijos o crear un campo calculado.

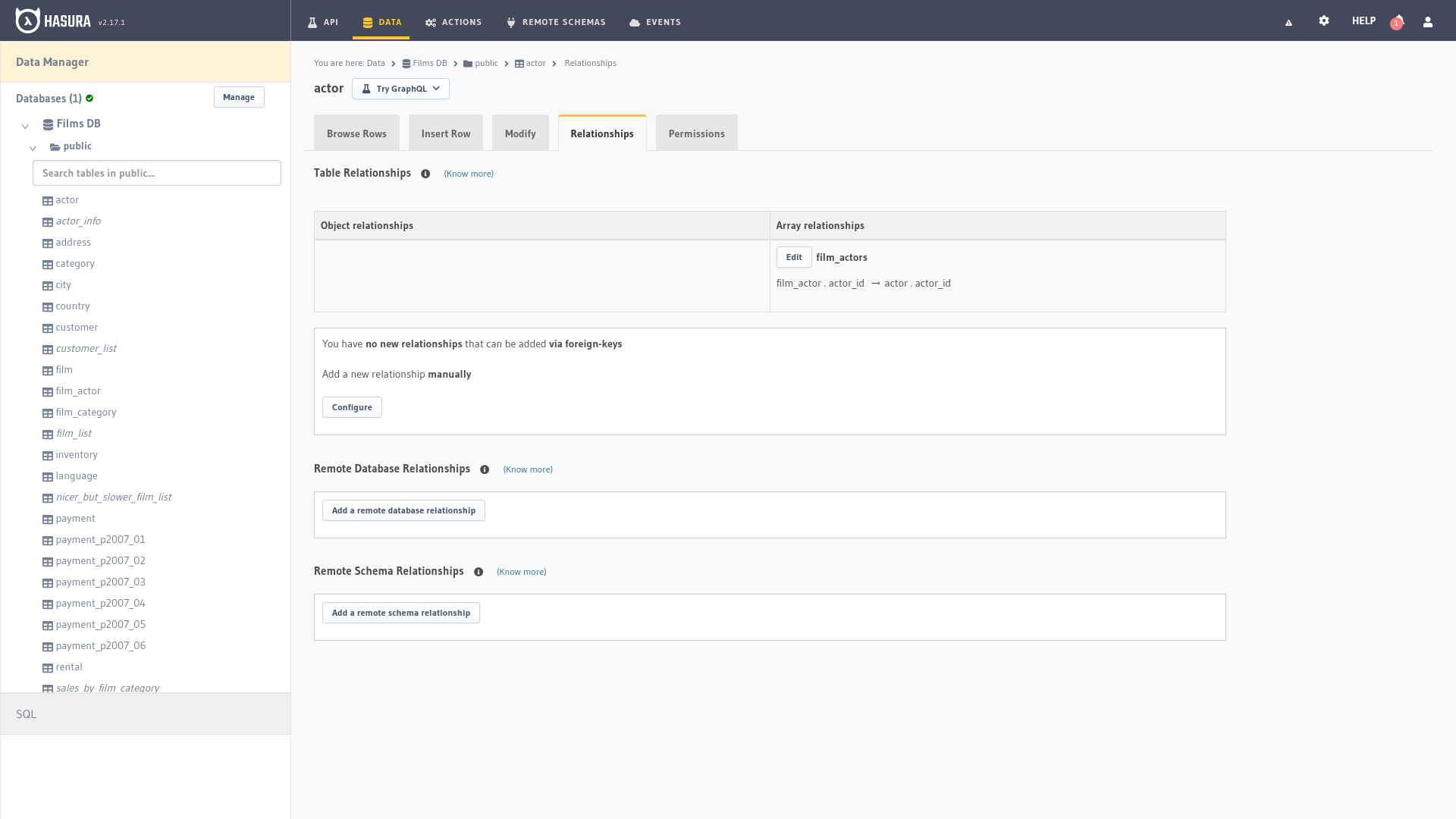
Relaciones
La pestaña Relationships (Relaciones) en el panel de administración de Hasura facilita la definición y gestión de relaciones entre tablas en la base de datos, nos proporciona una interfaz gráfica e intuitiva para establecer conexiones entre tablas, permitiendo la creación de consultas anidadas y la obtención de datos relacionados de manera eficiente a través de la API.
Al seleccionar una tabla específica en el panel de administración de Hasura se puede acceder a la pestaña «Relationships» para configurar las relaciones entre las tablas. Hasura identifica automáticamente las claves foráneas presentes en la tabla y sugiere relaciones posibles con otras tablas en función de la estructura de la base de datos.
Permisos
La sección de roles y permisos sirve para establecer los controles de acceso a los datos a través de las consultas a la API, quién puede insertar, acceder, modificar o eliminar qué datos y cómo, las variables que puede consultar, etc. Esto utilizando un sistema de roles y permisos lo suficientemente flexible cómo para cubrir la mayoría de casos de uso.
Por ejemplo un rol de usuario simple con acceso de consulta y modificación limitada, otro de tipo moderador que pueda modificar algunas tablas que el usuario no o un rol de usuario para los empleados que tengan permitido el acceso a determinadas tablas que el usuario básico y los de moderación no, etc.
Si seleccionamos en la izquierda la tabla city podremos crear los roles de usuario, en el campo de texto que pone Enter new role (Introducir nuevo rol) escribimos user y pulsamos sobre la cruz roja que hay en la columna Select, esto nos abrirá el formulario de configuración de los permisos:
Row select permissions: Nos permite establecer algún filtro utilizando las variables de la cabecera de la solicitud u otros campos de la base de datos, lo dejamos sin restricciones activandoWithout any checks.Column select permissions: Indica qué parámetros de la entidad se verán influenciados por esta regla. Presionamos el botónToggle allpara que nos active todos los campos haciéndolos así accesibles para este rol.Aggregation query permissions: Nos permite indicar si este rol de usuario tiene permisos para hacer consultas de agregación, como totales o promedios, máximos o mínimos. Podemos dejarlo como esta´.Root field permissions: Para gestionar los permisos del elemento raíz, si está desactivado se permiten todos por defecto.
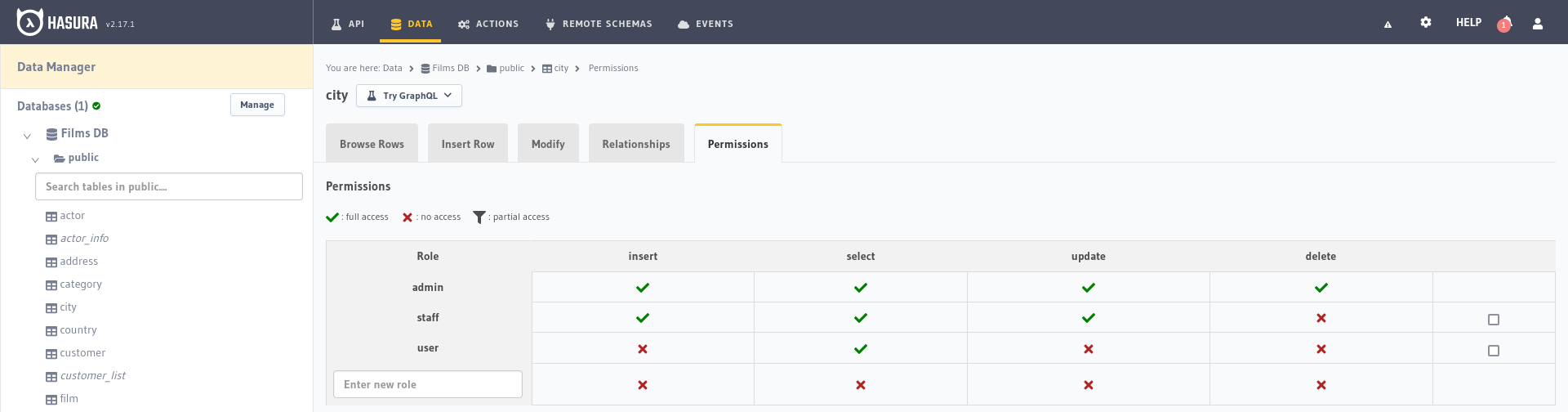
De esta forma habremos creado el nuevo rol de usuario user con permisos de selección en la tabla city sin ningún tipo de restricción en los parámetros a seleccionar, ahora podemos repetir el proceso para crear el rol staff y darle los permisos de inserción, selección y modificación necesarios.
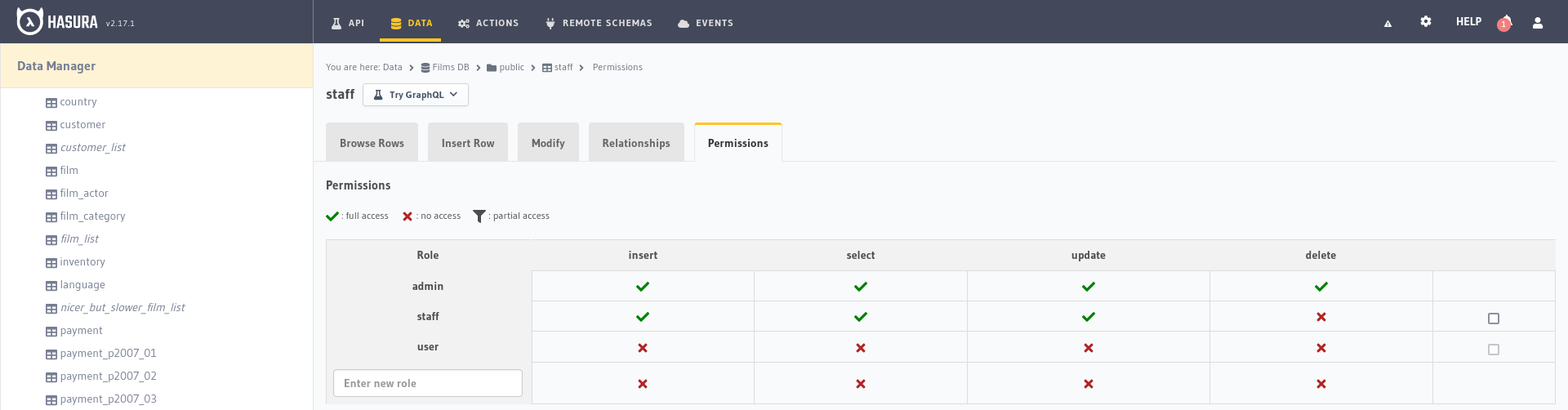
Para verificar que los permisos se están aplicando correctamente podemos ir a la pestaña API y añadir a la cabecera de la petición la clave x-hasura-role con el valor user, veremos que sólo podemos recoger los datos de city mientras que si lo cambiamos por staff podemos acceder (además de insertar y modificar) a mayores a la información de la tabla staff.

Acciones
Una acción es un evento que se ejecuta en el servidor tras una llamada a la API, nos permite ejecutar determinadas acciones que no corresponderían con las habituales, fuera de la lógica de negocio.

Imaginemos que en una de nuestras aplicaciones queremos mostrar el tiempo actual en una ciudad concreta, podríamos llamar directamente a Free Weather API de OpenMeteo desde el cliente o crear una acción en nuestro Hasura que actuaría de intermediaria y se encargaría de solicitar a OpenMeteo la temperatura cuando la llamásemos desde el cliente.
Este tipo de funcionalidades están pensadas para realizar gestiones relacionadas con nuestros datos que pueden requerir de algún tipo de operación especial, tal y cómo lo estamos haciendo ahora tiene el inconveniente de que se realizan dos peticiones en vez de la única que necesitaríamos si hiciéramos la petición directamente.
Es responsabilidad del equipo de desarrollo estimar ventajas y desventajas para decidir qué método es mejor para la casuística del proyecto en cuestión, esto es sólo un ejemplo.
Para empezar vamos a definir el formato de la acción, la solicitud que se realizará, en el recuadro Action Definiton.
type Query {
getLatLongTemperature(
latLongInput: LatLongInput!
): LatLongOutput
}En el siguiente recuadro Type Configuration creamos los tipos de datos, podríamos asociarlos con el concepto de Clase de la programación orientada a objetos, definen la estructura de los datos que se recibirán (Input) y responderán (Output) durante la ejecución de la acción.
input LatLongInput {
latitude: Float!
longitude: Float!
}
type LatLongOutput {
latitude: Float!
longitude: Float!
current_weather: CurrentWeatherOutput
}
type CurrentWeatherOutput {
temperature: Float!
windspeed: Float!
winddirection: Float!
weather_mode: Int!
time: String
}Tanto LatLongOutput como CurrentWeatherOutput (que es un subconjunto de datos del primero) se corresponden a la respuesta que recibiremos de la API de OpenMeteo, que es similar a la que se muestra a continuación:
{
"latitude": 51.5,
"longitude": -0.120000124,
"generationtime_ms": 0.2110004425048828,
"utc_offset_seconds": 0,
"timezone": "GMT",
"timezone_abbreviation": "GMT",
"elevation": 27.0,
"current_weather": {
"temperature": 5.0,
"windspeed": 5.9,
"winddirection": 259.0,
"weathercode": 0,
"time": "2023-01-30T20:00"
}
}Aquí recogemos las variables que puede que vayamos a utilizar en algún punto en alguno de los clientes, después en cada petición podremos especificar qué datos queremos exactamente en cada caso.
En el Webhook Handler tenemos que añadir la URL del endpoint al que se enviará la petición, en nuestro caso sería la de la API de OpenMeteo
Más abajo vamos a selecionar la opción para modificar las opciones de la solicitud (Add request options transform) que se envía a OpenMeteo para indicarle que queremos el tiempo actual de la latitud y longitud que le enviaremos.
Request method: GET{{$base_url}}: /v1/forecastcurrent_weather: truelatitude: {{$body.input.latLongInput.latitude}}longitude: {{$body.input.latLongInput.longitude}}
Utilizando {{$body.input.latLongInput.latitude}} accedemos al valor de la latitud en el cuerpo de la solicitud de entrada, una vez hayamos terminado debería mostrarnos una dirección temporal en el Preview de abajo:
https://api.open-meteo.com/v1/forecast?longitude=10&latitude=10¤t_weather=true
Enlace que podemos consultar directamente en el navegador para comprobar que funciona y devuelve los datos que esperamos.

Ahora podemos probar la acción desde el panel de administración de Hasura, en la pestaña API introducimos la siguiente consulta:
query GetLatLongTemperature {
getLatLongTemperature(latLongInput: {latitude: 10.4806, longitude: 66.9036}) {
latitude
longitude
current_weather {
temperature
time
weather_mode
winddirection
windspeed
}
}
}
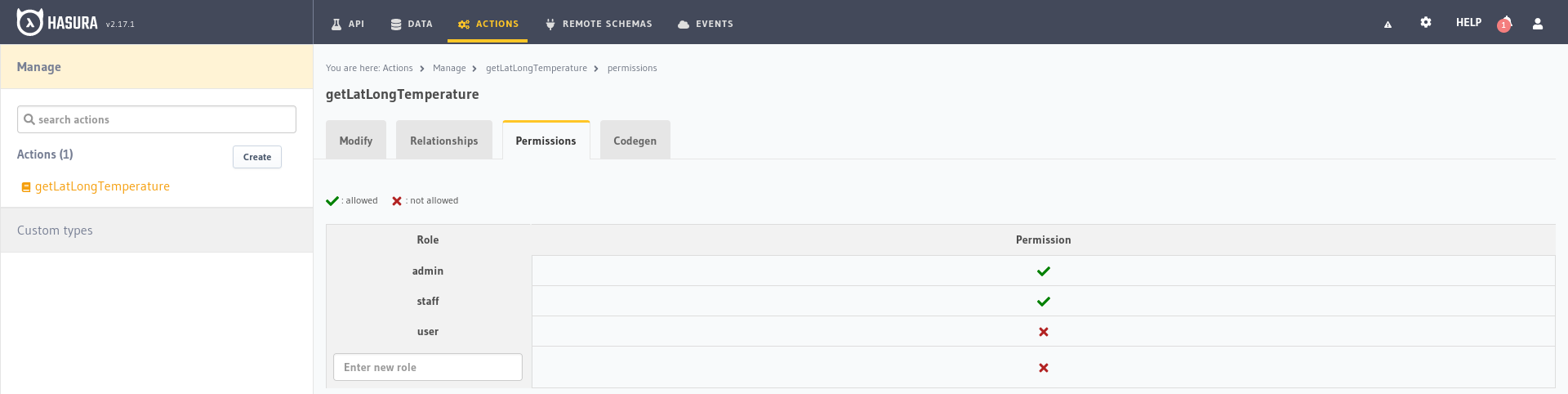
Podríamos también limitar el acceso a esta función utilizando los permisos igual que con las tablas de la base de datos. Suponiendo que la temperatura fuera una funcionalidad sólo disponible para los usuarios del personal se la restringimos para que sólo su rol pueda acceder desde la pestaña Permissions dentro de las opciones de la acción.
Esquemas remotos
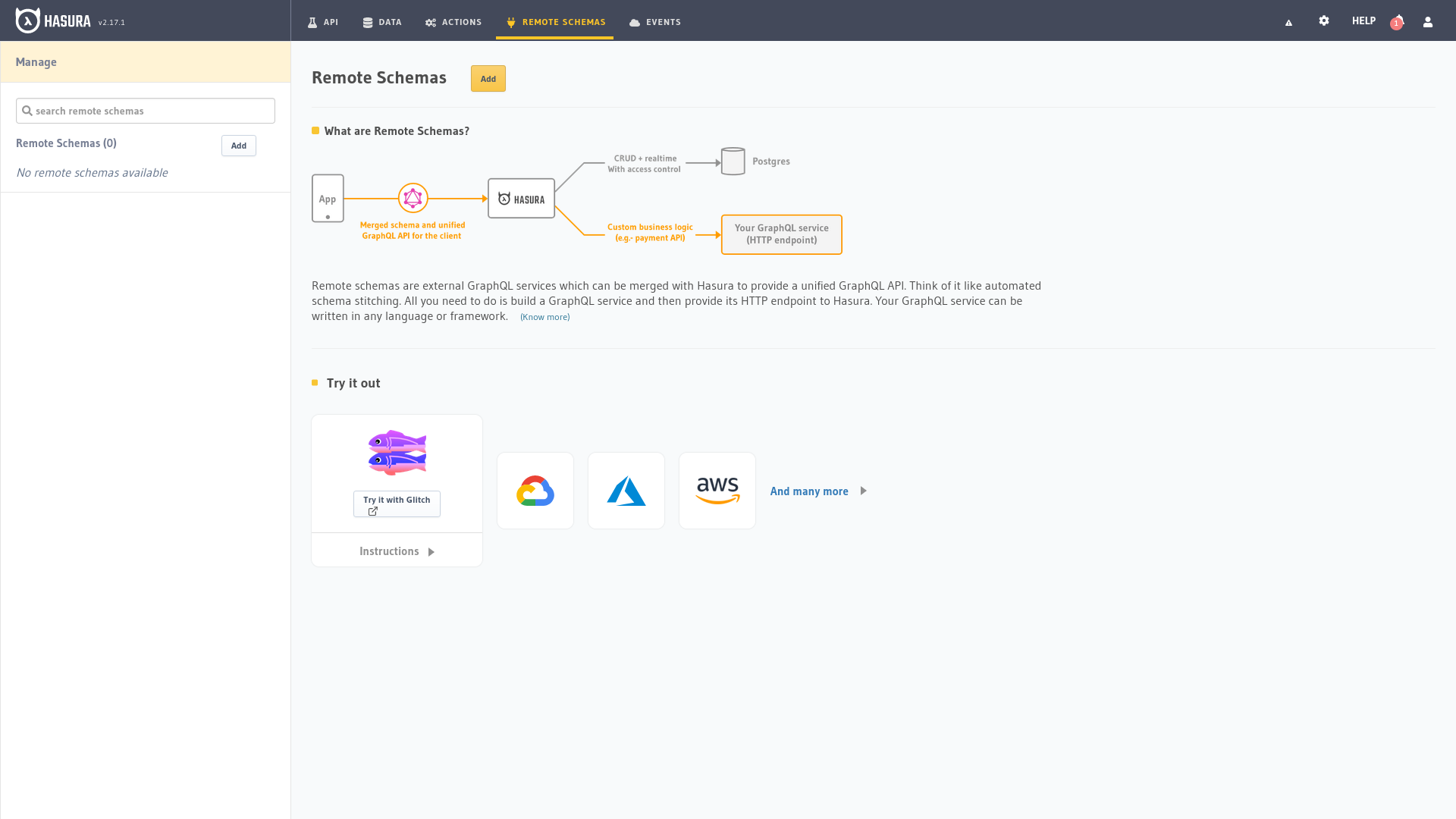
Los Remote Schemas (Esquemas remotos) en Hasura son una característica avanzada que permite a los desarrolladores combinar esquemas externos con el generado automáticamente por Hasura a partir de la base de datos. Esta funcionalidad proporciona una solución unificada para consultar y manipular datos de múltiples fuentes a través de una única API GraphQL, simplificando la arquitectura de aplicaciones y mejorando la experiencia de desarrollo.
Eventos
Los eventos a diferencia de las acciones se ejecutan automáticamente al realizarse una operación en la base de datos ya sea desde la API o desde cualquier otra fuente, el equivalente a los triggers en PostgreSQL.

Se utilizan principalmente para llamar a funciones serverless o webhooks que se ejecutarán cuando se produzca un evento. Para poder probarlo vamos a entrar en Webhook.site y copiar la URL que nos proporciona para ponerla en la configuración de nuestro evento.
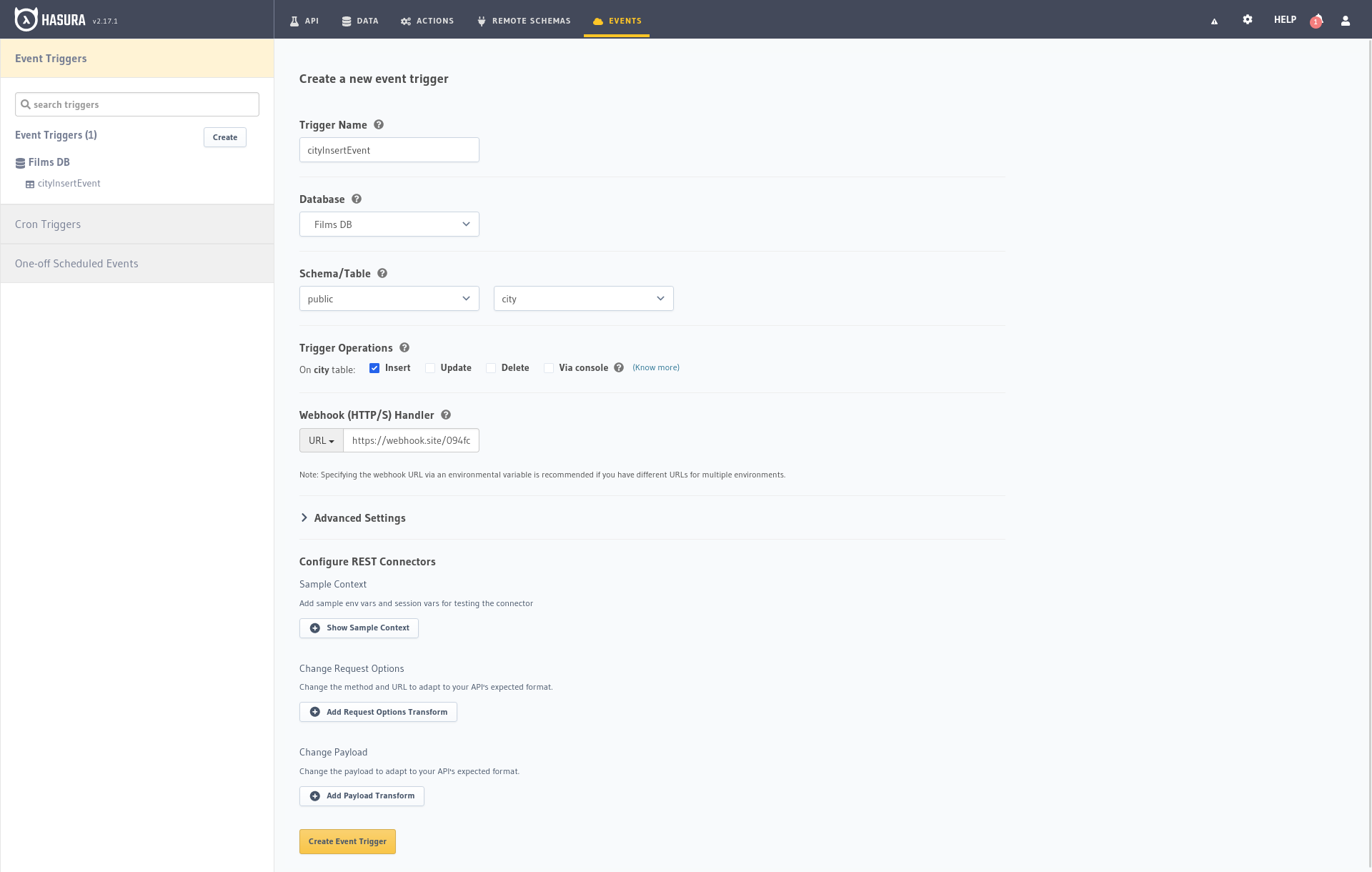
Rellenamos el formulario de la siguiente forma:
Event Name(Nombre): Le he puestocityInsertEventpero puedes ponerle el nombre que quierasDatabase(Base de datos):Films DB, el nombre que le hayamos puesto durante la creaciónSchema(Esquema): Utilizaremos el esquemapublic, por defecto en PostgreSQLTable(Tabla):cityo la tabla en la que queramos que se ejecute el eventoTrigger Operation(Operación): SeleccionamosInsertpara que nos notifique cada vez que se inserta una nueva ciudadWebhook URL(URL del Webhook): La dirección URL proporcionada por Webhook.site en el ejemplo
Ahora basta con insertar desde cualquier medio (el panel de Hasura mismo) una ciudad nueva para que nuestro evento se ejecute y nos notifique automáticamente
en el servidor que le hemos indicado con la URL. En el panel de Webhook.site nos aparecerá toda la información de la solicitud recibida con los datos que se insertaron si todo ha ido bien.
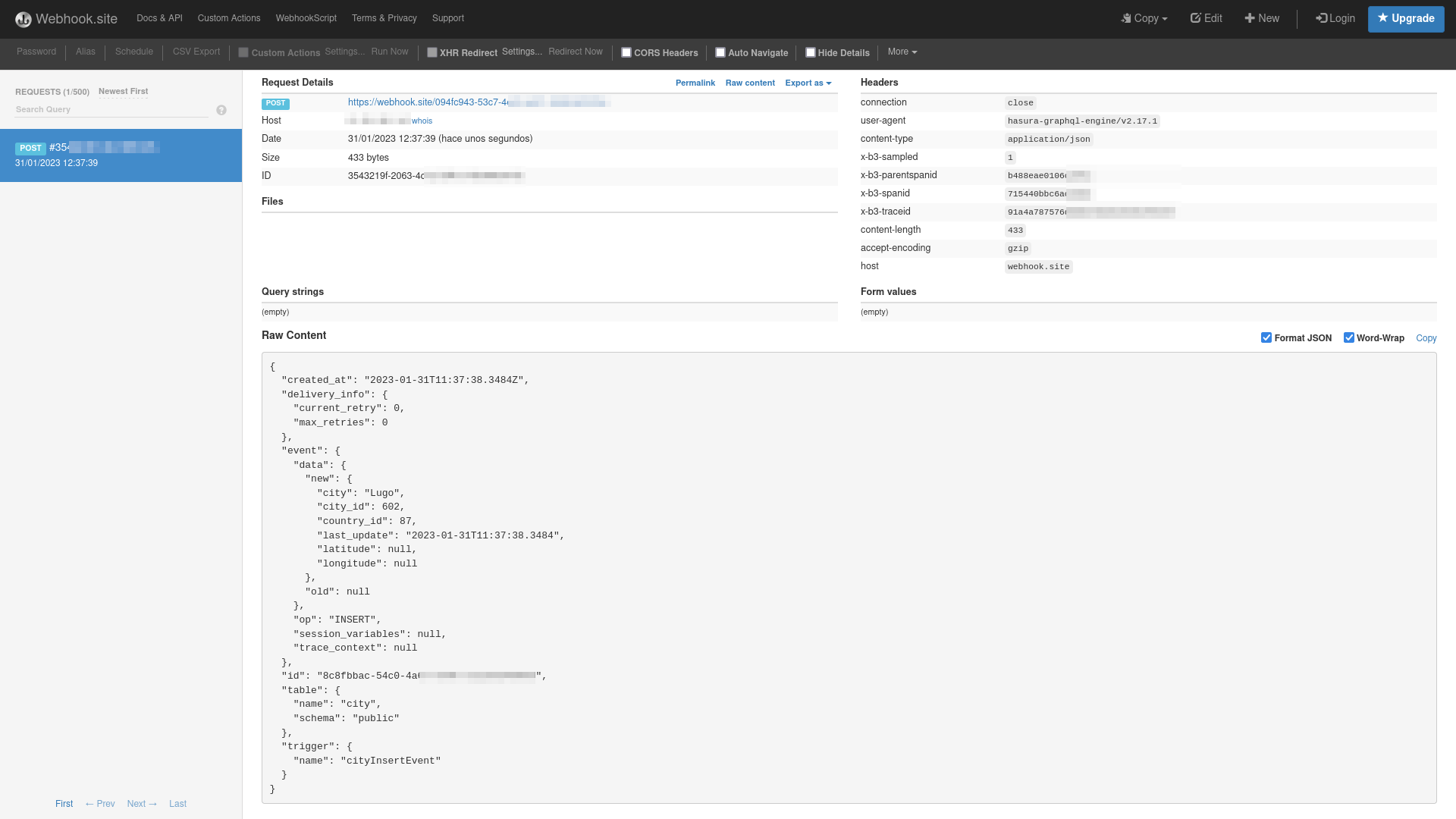
Al seleccionar el evento que acabamos de crear en el panel de administración de Hasura podemos ver las solicitudes procesadas, pendientes y los logs que guardan un registro de las llamadas a la función.

Los Cron triggers nos permiten ejecutar eventos periódicamente, por ejemplo para realizar una limpieza de la base de datos y los One-off scheduled events nos permiten ejecutar eventos programados en un momento determinado.
Aplicación cliente con Flutter
A continuación, exploraremos cómo desarrollar una aplicación cliente utilizando Flutter para nuestra solución móvil con el objetivo de consumir y gestionar los datos proporcionados por nuestra API. Esta aplicación de diseño intuitivo y fácil de usar permitirá a los usuarios visualizar una lista de películas, acceder a los detalles de cada título al seleccionarlo y, además, añadir y modificar elementos dentro de la base de datos.
Flutter es un marco de desarrollo de aplicaciones de código abierto creado por Google que permite a los desarrolladores crear aplicaciones móviles, web y de escritorio de alto rendimiento y visualmente atractivas a partir de una única base de código. Gracias a su enfoque multiplataforma Flutter facilita la creación de aplicaciones con interfaces de usuario nativas y personalizadas, brindando una experiencia consistente en diferentes plataformas y dispositivos. La utilización de Dart como lenguaje de programación y el motor de renderizado Skia, permiten a Flutter ofrecer un alto rendimiento y una rápida iteración en el proceso de desarrollo.
Para esta parte vamos a utilizar una base de datos predefinida que podemos descargar desde el repositorio de morenoh149 llamada Pagila que contiene información de un establecimiento de alquiler de películas (ficticias) que nos servirán para alimentar de datos el ejemplo. No olvides importar los datos correspondientes para no tener problemas durante el desarrollo.
En el proyecto de ejemplo se concentran varias funcionalidades bastante características como puede ser la lista ordenada alfabéticamente con selección por letra, el formulario para añadir nuevas películas o modificar y la pantalla con la información completa de la película seleccionada de la lista.
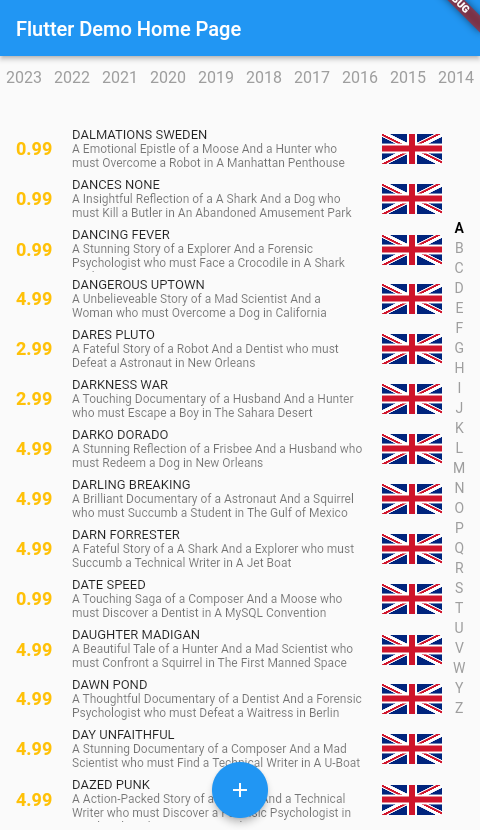
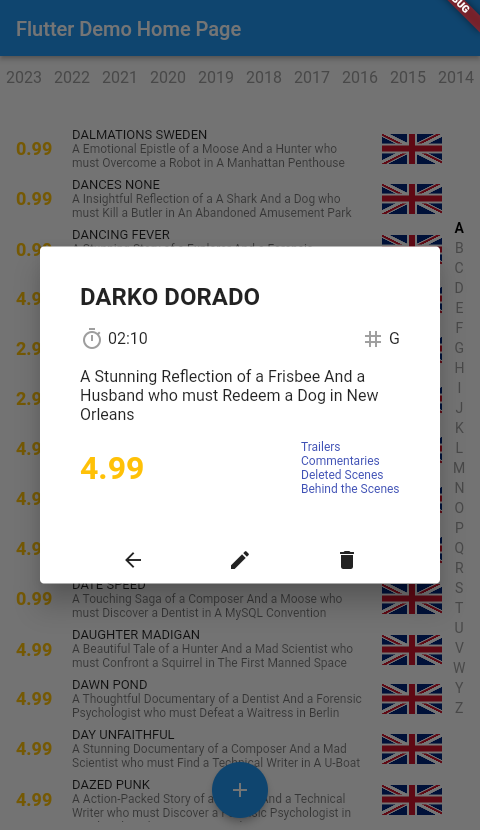
Una aplicación de ejemplo fácil de usar que aprovecha las múltiples capas y widgets proporcionados por el marco de Flutter, garantizando una separación clara entre el modelo de datos y la interfaz de usuario. Además, se encarga de actualizar y sincronizar los datos de manera eficiente en función de los eventos y acciones realizadas por el usuario en la aplicación.
Además, se puede apreciar de manera evidente la distinción entre un StatefulWidget y un StatelessWidget, los cuáles representan dos enfoques distintos para la gestión de estados en las aplicaciones Flutter:
- StatefulWidget: Un widget mutable cuyo estado puede cambiar a lo largo del tiempo. Este tipo de widget es adecuado para partes de la interfaz de usuario que requieren interacción del usuario o actualizaciones dinámicas en función de eventos externos. Un StatefulWidget consta de dos clases: una que hereda de StatefulWidget y otra que hereda de State, StatefulWidget sólo almacena la información de configuración, mientras que la clase State contiene el estado mutable y la lógica de la interfaz de usuario.
- StatelessWidget: Es por contra, inmutable, describe parte de la interfaz de usuario que no depende de estados dinámicos ni interacciones del usuario. Es ideal para componentes que permanecen constantes y no requieran cambios en su estructura o presentación a lo largo del tiempo. Un StatelessWidget consta de una sola clase que hereda de StatelessWidget y se basa en la información de configuración proporcionada durante la creación del widget.
Estas diferencias en la estructuración de la aplicación optimizan el rendimiento y facilitan la legibilidad y la mantenibilidad del código fuente, además, al utilizar StatefulWidget y StatelessWidget de manera adecuada se garantiza un manejo eficiente de los recursos y una mejor experiencia de usuario al interactuar con la aplicación.
En resumen, a lo largo de este artículo hemos explorado cómo crear una solución completa que combina la virtualización de la base de datos y Hasura virtualizándolas con Docker, la implementación de una API GraphQL y el desarrollo de una aplicación cliente en Flutter.
Hemos abordado cómo configurar y utilizar Docker para virtualizar nuestra base de datos PostgreSQL permitiendo una mayor portabilidad y facilidad de despliegue. Además hemos integrado Hasura para generar automáticamente una API GraphQL a partir de nuestra base de datos.
También hemos examinado las especificaciones completas de GraphQL destacando su flexibilidad para manejar consultas y mutaciones de datos en tiempo real. Asimismo hemos explorado las distintas partes del panel de administración de Hasura, como la creación de tablas, la definición de relaciones y la configuración de roles y permisos.
Por último, hemos desarrollado una aplicación cliente en Flutter que consume la API GraphQL proporcionada por Hasura, en la cúal hemos implementado una serie de funcionalidades clave como la visualización de una lista de películas, el acceso a los detalles de cada título y la adición y modificación de elementos en la base de datos, sumándole el selector por año.
En conjunto, este proyecto demuestra cómo se pueden combinar tecnologías modernas como Docker, Hasura y Flutter para crear soluciones robustas y escalables, optimizando el desarrollo y proporcionando una experiencia de usuario excepcional.
Cualquier duda o sugerencia puedes utilizar la parte de los comentarios.
Relacionado
- Código fuente: Codeberg
- Página principal de Docker: Docker
- Página principal de PostgreSQL: PostgreSQL
- Servicio en la nube de Hasura: Hasura
- Especificación GraphQL: Spec.GraphQL
- Especificación REST: W3C
- Lenguaje de programación Dart: Página principal
- Librería de gráficos 2D Skia: Página Principal
- Webhooks para pruebas: Webhook.site
- API abierta de datos meteorológicos: OpenMeteo
- Base de datos predefinida Pagila: Github de morenoh149
Desarrollador de software, informático, emprendedor y entusiasta por la tecnología desde tiempos inmemoriales. Inquieto por defecto, curioso por naturaleza, trato de entender el mundo y mejorarlo utilizando la tecnología como herramienta.